 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Input Gradients Highlight Discriminative Features?
Paper and Code
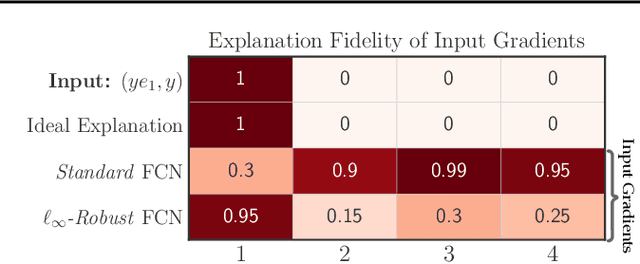

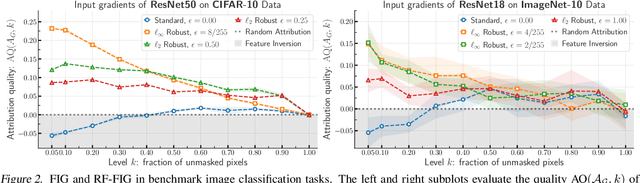
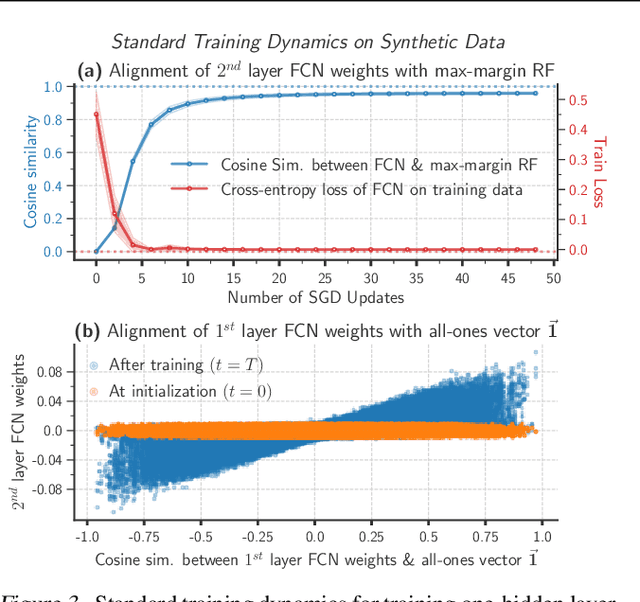
Interpretability methods that seek to explain instance-specific model predictions [Simonyan et al. 2014, Smilkov et al. 2017] are often based on the premise that the magnitude of input-gradient -- gradient of the loss with respect to input -- highlights discriminative features that are relevant for prediction over non-discriminative features that are irrelevant for prediction. In this work, we introduce an evaluation framework to study this hypothesis for benchmark image classification tasks, and make two surprising observations on CIFAR-10 and Imagenet-10 datasets: (a) contrary to conventional wisdom, input gradients of standard models (i.e., trained on the original data) actually highlight irrelevant features over relevant features; (b) however, input gradients of adversarially robust models (i.e., trained on adversarially perturbed data) starkly highlight relevant features over irrelevant features. To better understand input gradients, we introduce a synthetic testbed and theoretically justify our counter-intuitive empirical findings. Our observations motivate the need to formalize and verify common assumptions in interpretability, while our evaluation framework and synthetic dataset serve as a testbed to rigorously analyze instance-specific interpretability methods.