 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo ever larger octopi still amplify reporting biases? Evidence from judgments of typical colour
Paper and Code
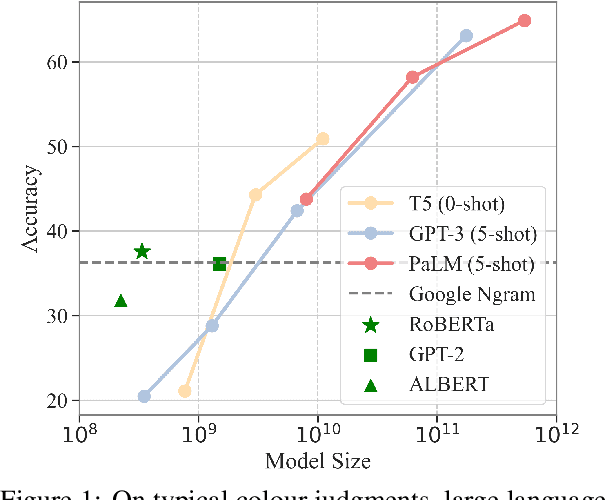



Language models (LMs) trained on raw texts have no direct access to the physical world. Gordon and Van Durme (2013) point out that LMs can thus suffer from reporting bias: texts rarely report on common facts, instead focusing on the unusual aspects of a situation. If LMs are only trained on text corpora and naively memorise local co-occurrence statistics, they thus naturally would learn a biased view of the physical world. While prior studies have repeatedly verified that LMs of smaller scales (e.g., RoBERTa, GPT-2) amplify reporting bias, it remains unknown whether such trends continue when models are scaled up. We investigate reporting bias from the perspective of colour in larger language models (LLMs) such as PaLM and GPT-3. Specifically, we query LLMs for the typical colour of objects, which is one simple type of perceptually grounded physical common sense. Surprisingly, we find that LLMs significantly outperform smaller LMs in determining an object's typical colour and more closely track human judgments, instead of overfitting to surface patterns stored in texts. This suggests that very large models of language alone are able to overcome certain types of reporting bias that are characterized by local co-occurrences.