 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLA: Dense-Layer-Analysis for Adversarial Example Detection
Paper and Code
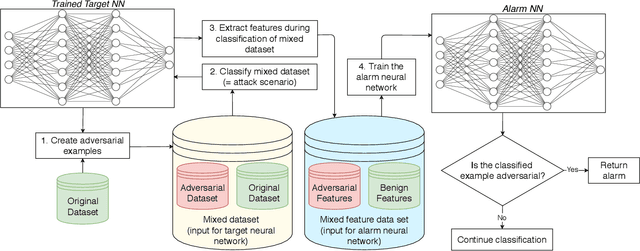
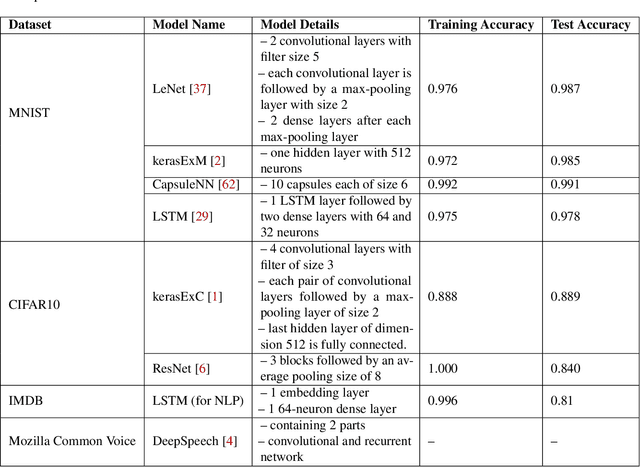


In recent years Deep Neural Networks (DNNs) have achieved remarkable results and even showed super-human capabilities in a broad range of domains. This led people to trust in DNNs' classifications and resulting actions even in security-sensitive environments like autonomous driving. Despite their impressive achievements, DNNs are known to be vulnerable to adversarial examples. Such inputs contain small perturbations to intentionally fool the attacked model. In this paper, we present a novel end-to-end framework to detect such attacks during classification without influencing the target model's performance. Inspired by recent research in neuron-coverage guided testing we show that dense layers of DNNs carry security-sensitive information. With a secondary DNN we analyze the activation patterns of the dense layers during classification runtime, which enables effective and real-time detection of adversarial examples. Our prototype implementation successfully detects adversarial examples in image, natural language, and audio processing. Thereby, we cover a variety of target DNNs, including Long Short Term Memory (LSTM) architectures. In addition, to effectively defend against state-of-the-art attacks, our approach generalizes between different sets of adversarial examples. Thus, our method most likely enables us to detect even future, yet unknown attacks. Finally, during white-box adaptive attacks, we show our method cannot be easily bypassed.