 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Plausible Shape Completions from Ambiguous Depth Images
Paper and Code

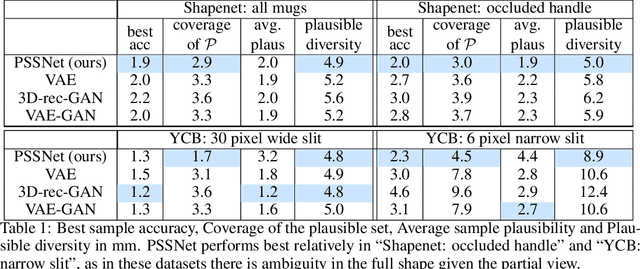
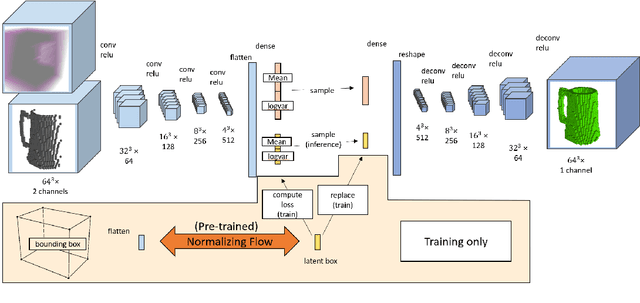

We propose PSSNet, a network architecture for generating diverse plausible 3D reconstructions from a single 2.5D depth image. Existing methods tend to produce only small variations on a single shape, even when multiple shapes are consistent with an observation. To obtain diversity we alter a Variational Auto Encoder by providing a learned shape bounding box feature as side information during training. Since these features are known during training, we are able to add a supervised loss to the encoder and noiseless values to the decoder. To evaluate, we sample a set of completions from a network, construct a set of plausible shape matches for each test observation, and compare using our plausible diversity metric defined over sets of shapes. We perform experiments using Shapenet mugs and partially-occluded YCB objects and find that our method performs comparably in datasets with little ambiguity, and outperforms existing methods when many shapes plausibly fit an observed depth image. We demonstrate one use for PSSNet on a physical robot when grasping objects in occlusion and clutter.