Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Ensembles Improve Calibration
Paper and Code
Jul 08, 2020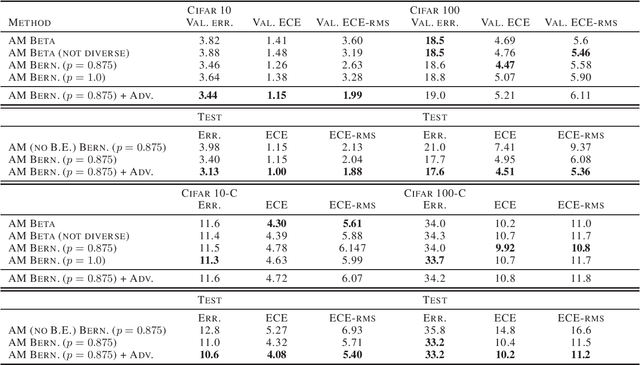
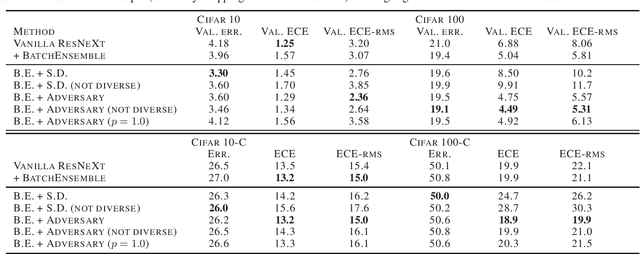
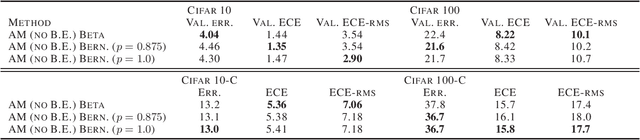
Modern deep neural networks can produce badly calibrated predictions, especially when train and test distributions are mismatched. Training an ensemble of models and averaging their predictions can help alleviate these issues. We propose a simple technique to improve calibration, using a different data augmentation for each ensemble member. We additionally use the idea of `mixing' un-augmented and augmented inputs to improve calibration when test and training distributions are the same. These simple techniques improve calibration and accuracy over strong baselines on the CIFAR10 and CIFAR100 benchmarks, and out-of-domain data from their corrupted versions.
* Presented at the ICML 2020 Workshop on Uncertainty and Robustness in
Deep Learning
View paper on