 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivEMT: Neural Machine Translation Post-Editing Effort Across Typologically Diverse Languages
Paper and Code

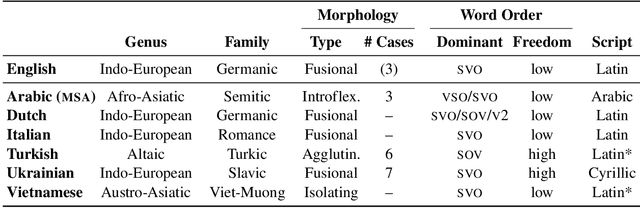
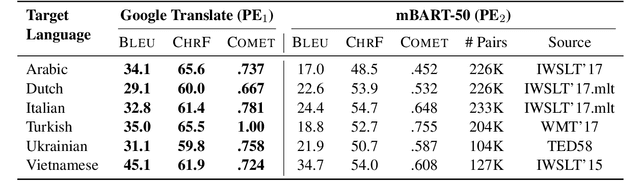
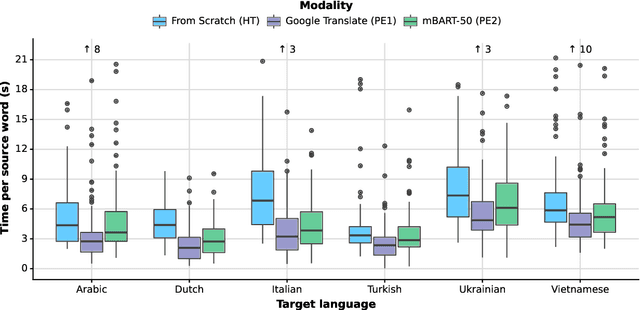
We introduce DivEMT, the first publicly available post-editing study of Neural Machine Translation (NMT) over a typologically diverse set of target languages. Using a strictly controlled setup, 18 professional translators were instructed to translate or post-edit the same set of English documents into Arabic, Dutch, Italian, Turkish, Ukrainian, and Vietnamese. During the process, their edits, keystrokes, editing times, pauses, and perceived effort were recorded, enabling an in-depth, cross-lingual evaluation of NMT quality and its post-editing process. Using this new dataset, we assess the impact on translation productivity of two state-of-the-art NMT systems, namely: Google Translate and the open-source multilingual model mBART50. We find that, while post-editing is consistently faster than translation from scratch, the magnitude of its contribution varies largely across systems and languages, ranging from doubled productivity in Dutch and Italian to marginal gains in Arabic, Turkish and Ukrainian, for some of the evaluated modalities. Moreover, the observed cross-language variability appears to partly reflect source-target relatedness and type of target morphology, while remaining hard to predict even based on state-of-the-art automatic MT quality metrics. We publicly release the complete dataset, including all collected behavioural data, to foster new research on the ability of state-of-the-art NMT systems to generate text in typologically diverse languages.