 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDive into Big Model Training
Paper and Code

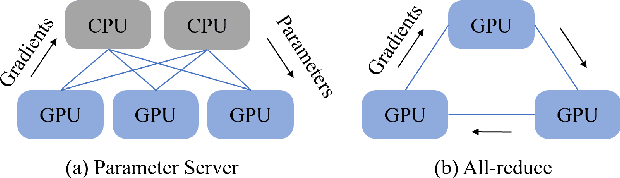
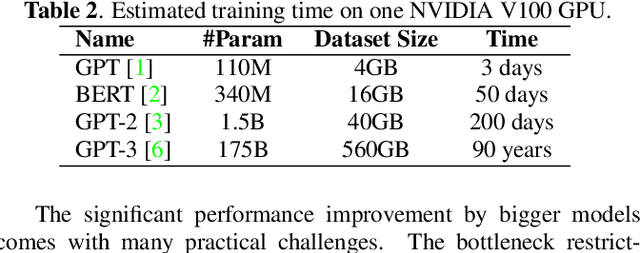

The increasing scale of model size and continuous improvement of performance herald the arrival of the Big Model era. In this report, we explore what and how the big model training works by diving into training objectives and training methodologies. Specifically,training objectives describe how to leverage web-scale data to develop extremely capable and incredibly large models based on self-supervised learning, and training methodologies which are based on distributed training describe how to make big model training a reality. We summarize the existing training methodologies into three main categories: training parallelism, memory-saving technologies, and model sparsity design. Training parallelism can be categorized into data, pipeline, and tensor parallelism according to the dimension of parallelism that takes place. Memory-saving technologies are orthogonal and complementary to training parallelism. And model sparsity design further scales up the model size with a constant computational cost. A continuously updated paper list of big model training is provided at https://github.com/qhliu26/BM-Training.