 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-free uncertainty quantification for classification under label shift
Paper and Code
Mar 11, 2021
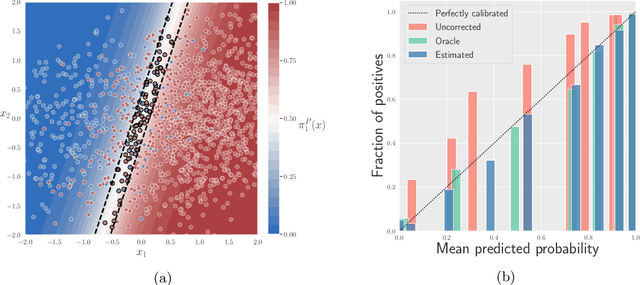

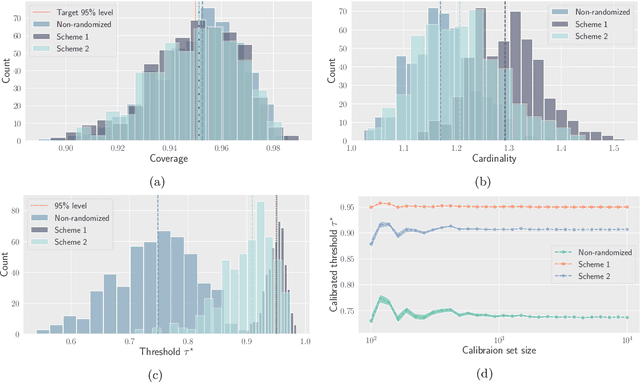
Trustworthy deployment of ML models requires a proper measure of uncertainty, especially in safety-critical applications. We focus on uncertainty quantification (UQ) for classification problems via two avenues -- prediction sets using conformal prediction and calibration of probabilistic predictors by post-hoc binning -- since these possess distribution-free guarantees for i.i.d. data. Two common ways of generalizing beyond the i.i.d. setting include handling covariate and label shift. Within the context of distribution-free UQ, the former has already received attention, but not the latter. It is known that label shift hurts prediction, and we first argue that it also hurts UQ, by showing degradation in coverage and calibration. Piggybacking on recent progress in addressing label shift (for better prediction), we examine the right way to achieve UQ by reweighting the aforementioned conformal and calibration procedures whenever some unlabeled data from the target distribution is available. We examine these techniques theoretically in a distribution-free framework and demonstrate their excellent practical performance.