 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution free optimality intervals for clustering
Paper and Code
Jul 30, 2021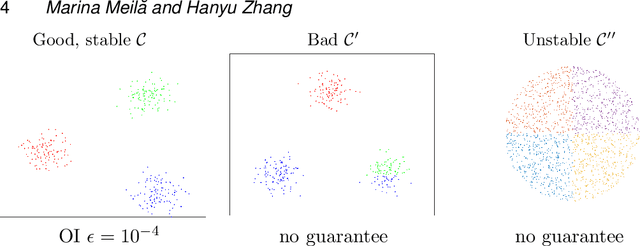
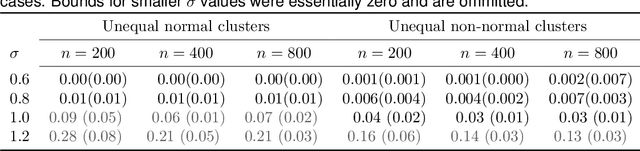
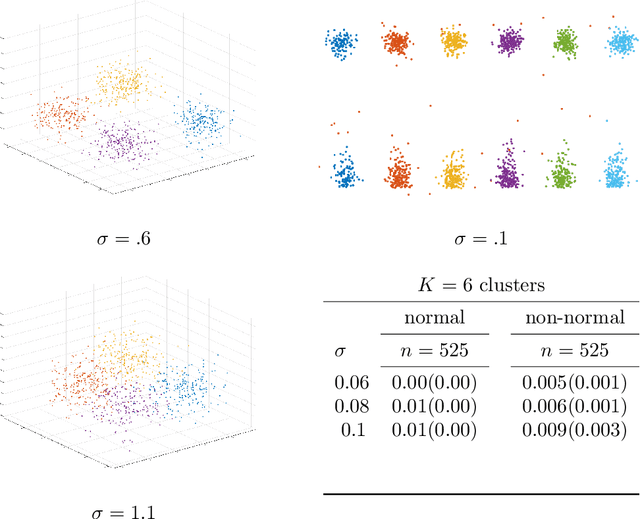
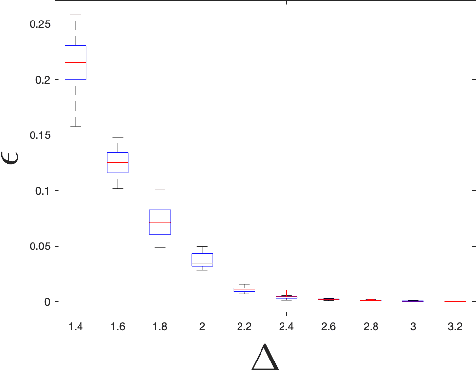
We address the problem of validating the ouput of clustering algorithms. Given data $\mathcal{D}$ and a partition $\mathcal{C}$ of these data into $K$ clusters, when can we say that the clusters obtained are correct or meaningful for the data? This paper introduces a paradigm in which a clustering $\mathcal{C}$ is considered meaningful if it is good with respect to a loss function such as the K-means distortion, and stable, i.e. the only good clustering up to small perturbations. Furthermore, we present a generic method to obtain post-inference guarantees of near-optimality and stability for a clustering $\mathcal{C}$. The method can be instantiated for a variety of clustering criteria (also called loss functions) for which convex relaxations exist. Obtaining the guarantees amounts to solving a convex optimization problem. We demonstrate the practical relevance of this method by obtaining guarantees for the K-means and the Normalized Cut clustering criteria on realistic data sets. We also prove that asymptotic instability implies finite sample instability w.h.p., allowing inferences about the population clusterability from a sample. The guarantees do not depend on any distributional assumptions, but they depend on the data set $\mathcal{D}$ admitting a stable clustering.