 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Transmission Control for Wireless Networks using Multi-Agent Reinforcement Learning
Paper and Code
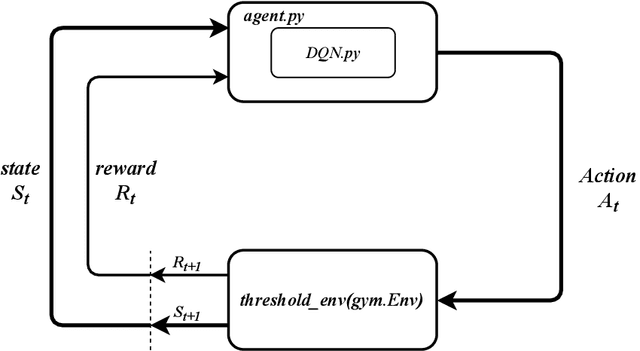
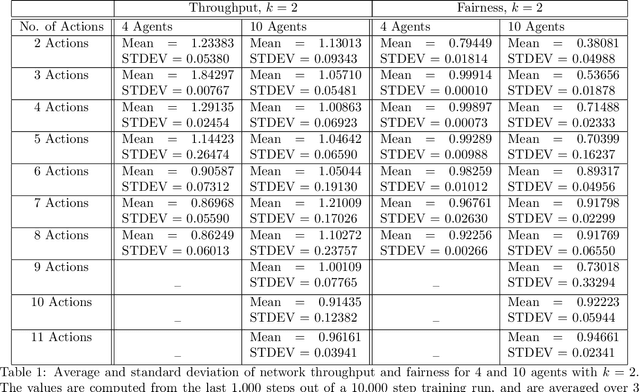
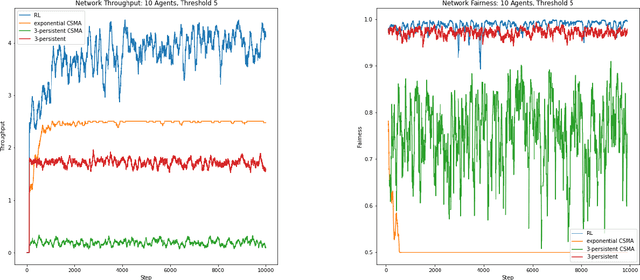
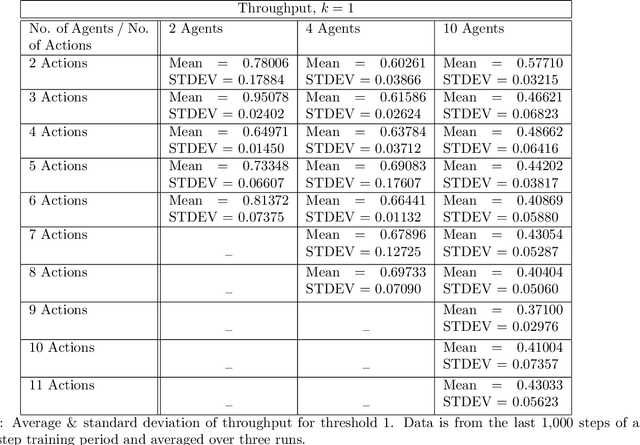
We examine the problem of transmission control, i.e., when to transmit, in distributed wireless communications networks through the lens of multi-agent reinforcement learning. Most other works using reinforcement learning to control or schedule transmissions use some centralized control mechanism, whereas our approach is fully distributed. Each transmitter node is an independent reinforcement learning agent and does not have direct knowledge of the actions taken by other agents. We consider the case where only a subset of agents can successfully transmit at a time, so each agent must learn to act cooperatively with other agents. An agent may decide to transmit a certain number of steps into the future, but this decision is not communicated to the other agents, so it the task of the individual agents to attempt to transmit at appropriate times. We achieve this collaborative behavior through studying the effects of different actions spaces. We are agnostic to the physical layer, which makes our approach applicable to many types of networks. We submit that approaches similar to ours may be useful in other domains that use multi-agent reinforcement learning with independent agents.