 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Stochastic Algorithms for High-rate Streaming Principal Component Analysis
Paper and Code
Jan 04, 2020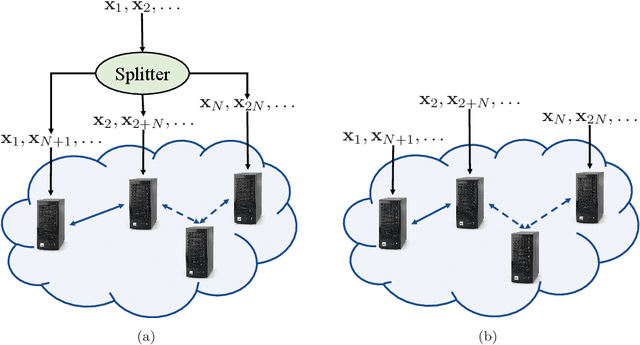
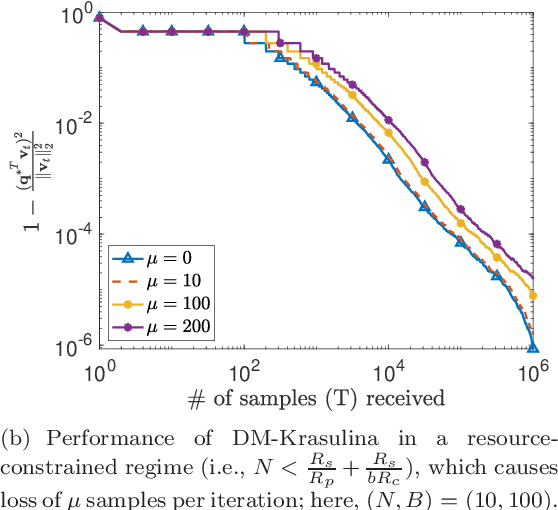
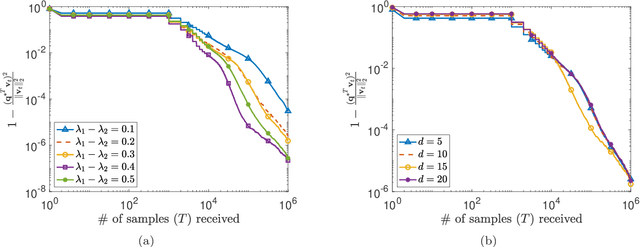
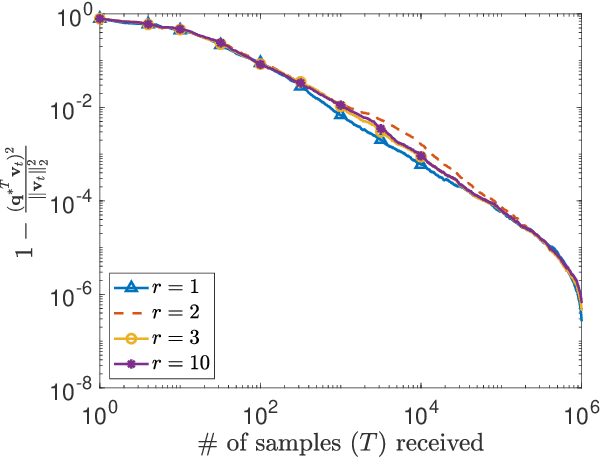
This paper considers the problem of estimating the principal eigenvector of a covariance matrix from independent and identically distributed data samples in streaming settings. The streaming rate of data in many contemporary applications can be high enough that a single processor cannot finish an iteration of existing methods for eigenvector estimation before a new sample arrives. This paper formulates and analyzes a distributed variant of the classical Krasulina's method (D-Krasulina) that can keep up with the high streaming rate of data by distributing the computational load across multiple processing nodes. The analysis shows that---under appropriate conditions---D-Krasulina converges to the principal eigenvector in an order-wise optimal manner; i.e., after receiving $M$ samples across all nodes, its estimation error can be $O(1/M)$. In order to reduce the network communication overhead, the paper also develops and analyzes a mini-batch extension of D-Krasulina, which is termed DM-Krasulina. The analysis of DM-Krasulina shows that it can also achieve order-optimal estimation error rates under appropriate conditions, even when some samples have to be discarded within the network due to communication latency. Finally, experiments are performed over synthetic and real-world data to validate the convergence behaviors of D-Krasulina and DM-Krasulina in high-rate streaming settings.