 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multi-Task Learning for Stochastic Bandits with Context Distribution and Stage-wise Constraints
Paper and Code

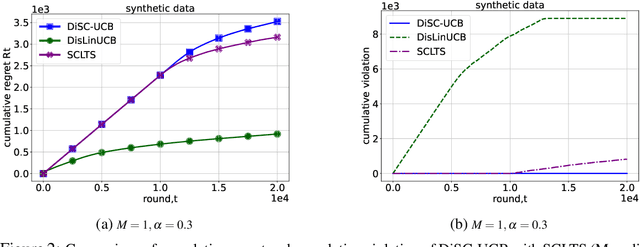
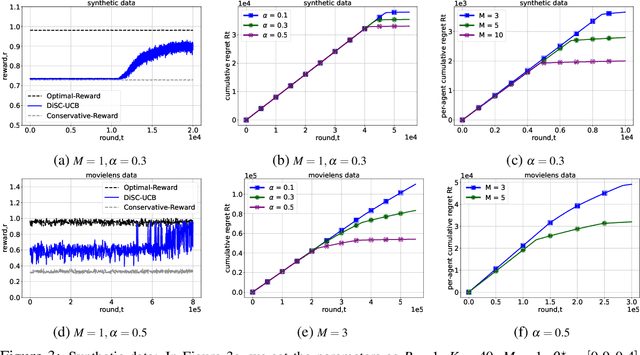
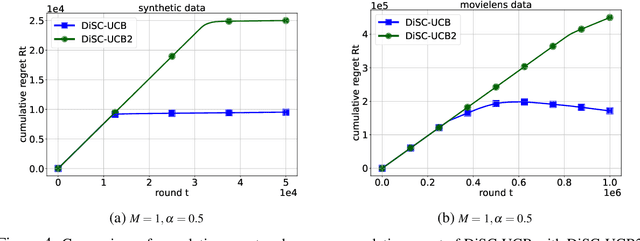
We present the problem of conservative distributed multi-task learning in stochastic linear contextual bandits with heterogeneous agents. This extends conservative linear bandits to a distributed setting where M agents tackle different but related tasks while adhering to stage-wise performance constraints. The exact context is unknown, and only a context distribution is available to the agents as in many practical applications that involve a prediction mechanism to infer context, such as stock market prediction and weather forecast. We propose a distributed upper confidence bound (UCB) algorithm, DiSC-UCB. Our algorithm constructs a pruned action set during each round to ensure the constraints are met. Additionally, it includes synchronized sharing of estimates among agents via a central server using well-structured synchronization steps. We prove the regret and communication bounds on the algorithm. We extend the problem to a setting where the agents are unaware of the baseline reward. For this setting, we provide a modified algorithm, DiSC-UCB2, and we show that the modified algorithm achieves the same regret and communication bounds. We empirically validated the performance of our algorithm on synthetic data and real-world Movielens-100K data.