 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning With Sparsified Gradient Differences
Paper and Code
Feb 05, 2022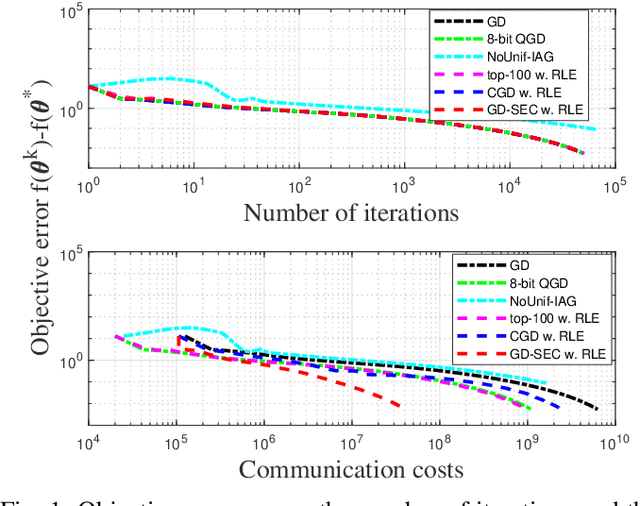

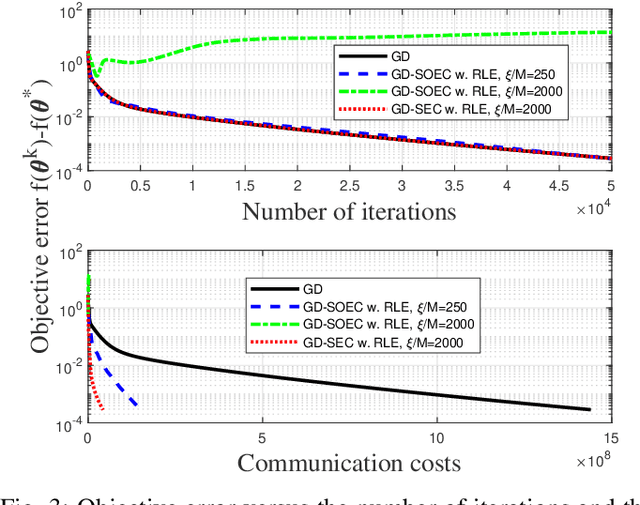

A very large number of communications are typically required to solve distributed learning tasks, and this critically limits scalability and convergence speed in wireless communications applications. In this paper, we devise a Gradient Descent method with Sparsification and Error Correction (GD-SEC) to improve the communications efficiency in a general worker-server architecture. Motivated by a variety of wireless communications learning scenarios, GD-SEC reduces the number of bits per communication from worker to server with no degradation in the order of the convergence rate. This enables larger-scale model learning without sacrificing convergence or accuracy. At each iteration of GD-SEC, instead of directly transmitting the entire gradient vector, each worker computes the difference between its current gradient and a linear combination of its previously transmitted gradients, and then transmits the sparsified gradient difference to the server. A key feature of GD-SEC is that any given component of the gradient difference vector will not be transmitted if its magnitude is not sufficiently large. An error correction technique is used at each worker to compensate for the error resulting from sparsification. We prove that GD-SEC is guaranteed to converge for strongly convex, convex, and nonconvex optimization problems with the same order of convergence rate as GD. Furthermore, if the objective function is strongly convex, GD-SEC has a fast linear convergence rate. Numerical results not only validate the convergence rate of GD-SEC but also explore the communication bit savings it provides. Given a target accuracy, GD-SEC can significantly reduce the communications load compared to the best existing algorithms without slowing down the optimization process.