 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning of Deep Neural Networks using Independent Subnet Training
Paper and Code
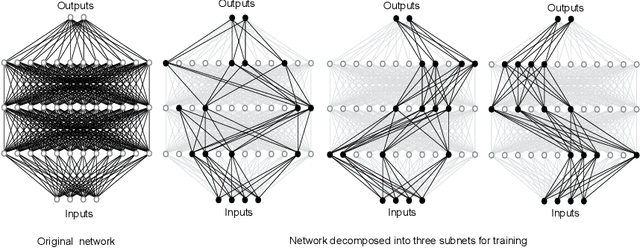
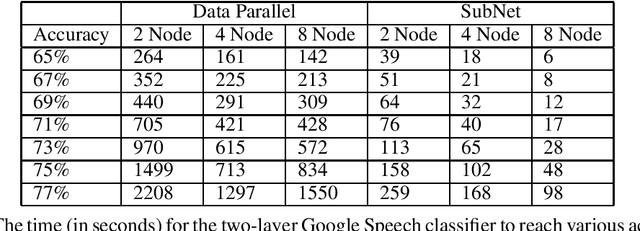
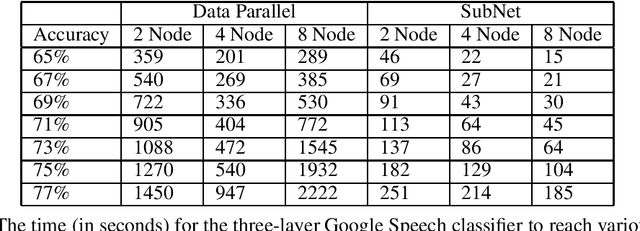

Stochastic gradient descent (SGD) is the method of choice for distributed machine learning, by virtue of its light complexity per iteration on compute nodes, leading to almost linear speedups in theory. Nevertheless, such speedups are rarely observed in practice, due to high communication overheads during synchronization steps. We alleviate this problem by introducing independent subnet training: a simple, jointly model-parallel and data-parallel, approach to distributed training for fully connected, feed-forward neural networks. During subnet training, neurons are stochastically partitioned without replacement, and each partition is sent only to a single worker. This reduces the overall synchronization overhead, as each worker only receives the weights associated with the subnetwork it has been assigned to. Subnet training also reduces synchronization frequency: since workers train disjoint portions of the network, the training can proceed for long periods of time before synchronization, similar to local SGD approaches. We empirically evaluate our approach on real-world speech recognition and product recommendation applications, where we observe that subnet training i) results into accelerated training times, as compared to state of the art distributed models, and ii) often results into boosting the testing accuracy, as it implicitly combines dropout and batch normalization regularizations during training.