 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Hessian-Free Optimization for Deep Neural Network
Paper and Code
Jan 15, 2017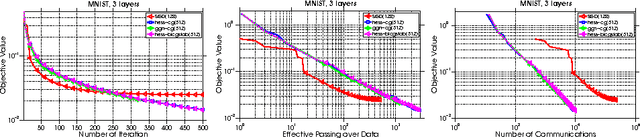
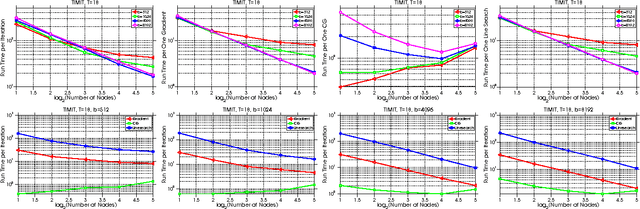
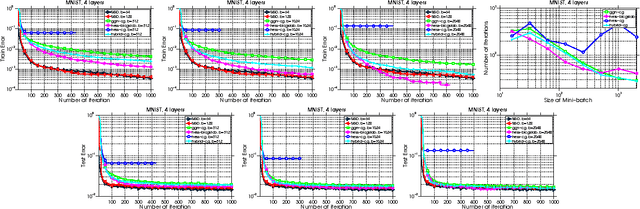
Training deep neural network is a high dimensional and a highly non-convex optimization problem. Stochastic gradient descent (SGD) algorithm and it's variations are the current state-of-the-art solvers for this task. However, due to non-covexity nature of the problem, it was observed that SGD slows down near saddle point. Recent empirical work claim that by detecting and escaping saddle point efficiently, it's more likely to improve training performance. With this objective, we revisit Hessian-free optimization method for deep networks. We also develop its distributed variant and demonstrate superior scaling potential to SGD, which allows more efficiently utilizing larger computing resources thus enabling large models and faster time to obtain desired solution. Furthermore, unlike truncated Newton method (Marten's HF) that ignores negative curvature information by using na\"ive conjugate gradient method and Gauss-Newton Hessian approximation information - we propose a novel algorithm to explore negative curvature direction by solving the sub-problem with stabilized bi-conjugate method involving possible indefinite stochastic Hessian information. We show that these techniques accelerate the training process for both the standard MNIST dataset and also the TIMIT speech recognition problem, demonstrating robust performance with upto an order of magnitude larger batch sizes. This increased scaling potential is illustrated with near linear speed-up on upto 16 CPU nodes for a simple 4-layer network.