 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinct patterns of syntactic agreement errors in recurrent networks and humans
Paper and Code
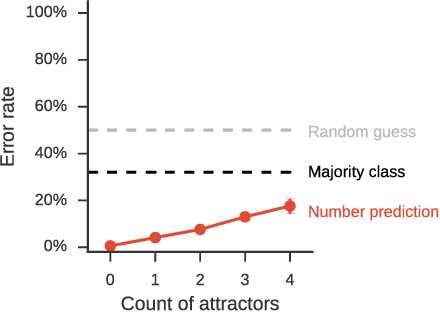
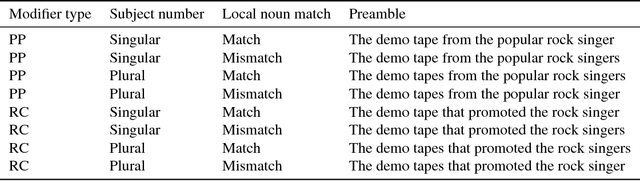
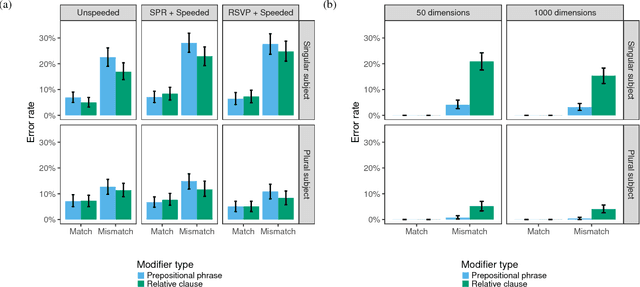
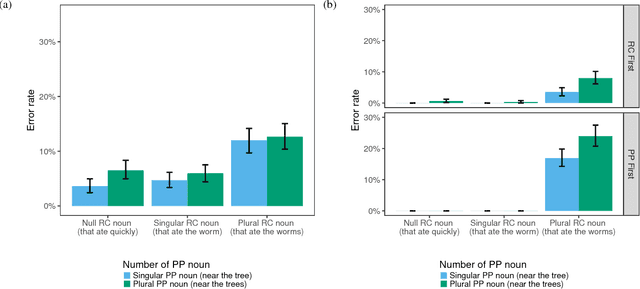
Determining the correct form of a verb in context requires an understanding of the syntactic structure of the sentence. Recurrent neural networks have been shown to perform this task with an error rate comparable to humans, despite the fact that they are not designed with explicit syntactic representations. To examine the extent to which the syntactic representations of these networks are similar to those used by humans when processing sentences, we compare the detailed pattern of errors that RNNs and humans make on this task. Despite significant similarities (attraction errors, asymmetry between singular and plural subjects), the error patterns differed in important ways. In particular, in complex sentences with relative clauses error rates increased in RNNs but decreased in humans. Furthermore, RNNs showed a cumulative effect of attractors but humans did not. We conclude that at least in some respects the syntactic representations acquired by RNNs are fundamentally different from those used by humans.