 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistantly Labeling Data for Large Scale Cross-Document Coreference
Paper and Code
May 24, 2010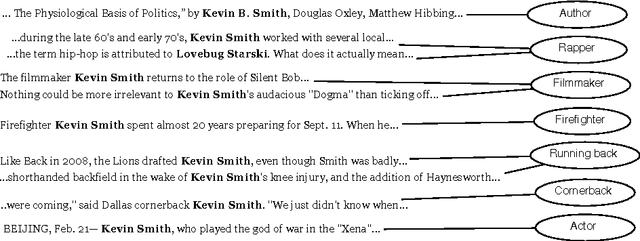
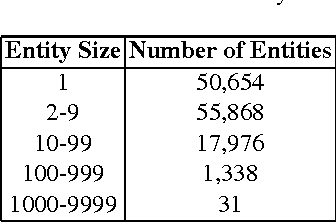


Cross-document coreference, the problem of resolving entity mentions across multi-document collections, is crucial to automated knowledge base construction and data mining tasks. However, the scarcity of large labeled data sets has hindered supervised machine learning research for this task. In this paper we develop and demonstrate an approach based on ``distantly-labeling'' a data set from which we can train a discriminative cross-document coreference model. In particular we build a dataset of more than a million people mentions extracted from 3.5 years of New York Times articles, leverage Wikipedia for distant labeling with a generative model (and measure the reliability of such labeling); then we train and evaluate a conditional random field coreference model that has factors on cross-document entities as well as mention-pairs. This coreference model obtains high accuracy in resolving mentions and entities that are not present in the training data, indicating applicability to non-Wikipedia data. Given the large amount of data, our work is also an exercise demonstrating the scalability of our approach.