Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled-Transformer: An Explainable End-to-End Automatic Speech Recognition Model with Speech Content-Context Separation
Paper and Code

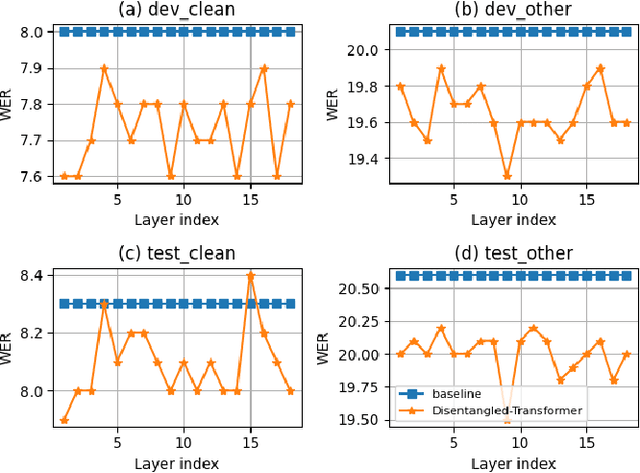

End-to-end transformer-based automatic speech recognition (ASR) systems often capture multiple speech traits in their learned representations that are highly entangled, leading to a lack of interpretability. In this study, we propose the explainable Disentangled-Transformer, which disentangles the internal representations into sub-embeddings with explicit content and speaker traits based on varying temporal resolutions. Experimental results show that the proposed Disentangled-Transformer produces a clear speaker identity, separated from the speech content, for speaker diarization while improving ASR performance.
* Accepted by the 6th IEEE International Conference on Image Processing
Applications and Systems
View paper on