Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Speech Representation Learning for One-Shot Cross-lingual Voice Conversion Using $β$-VAE
Paper and Code
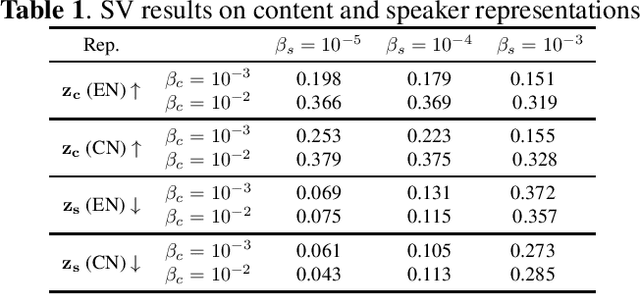
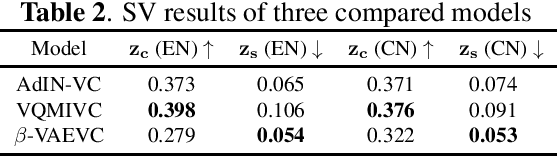
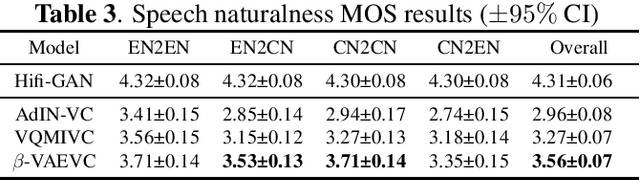
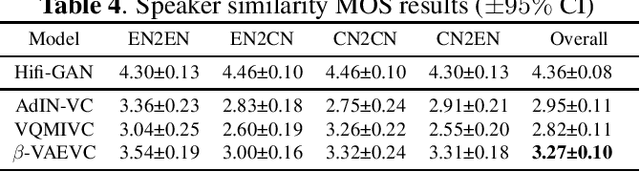
We propose an unsupervised learning method to disentangle speech into content representation and speaker identity representation. We apply this method to the challenging one-shot cross-lingual voice conversion task to demonstrate the effectiveness of the disentanglement. Inspired by $\beta$-VAE, we introduce a learning objective that balances between the information captured by the content and speaker representations. In addition, the inductive biases from the architectural design and the training dataset further encourage the desired disentanglement. Both objective and subjective evaluations show the effectiveness of the proposed method in speech disentanglement and in one-shot cross-lingual voice conversion.
* Accepted at SLT 2022
View paper on