Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete linear-complexity reinforcement learning in continuous action spaces for Q-learning algorithms
Paper and Code
Jul 23, 2018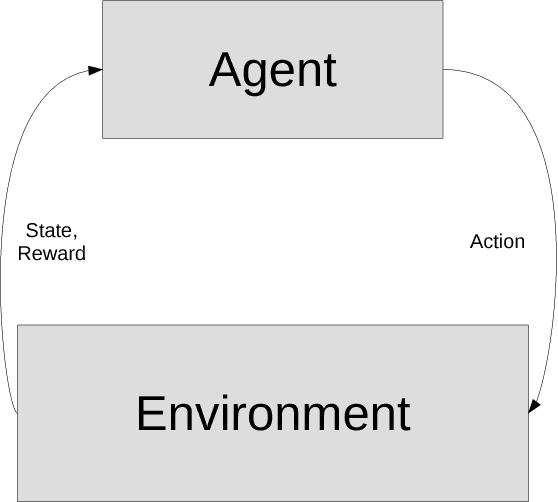

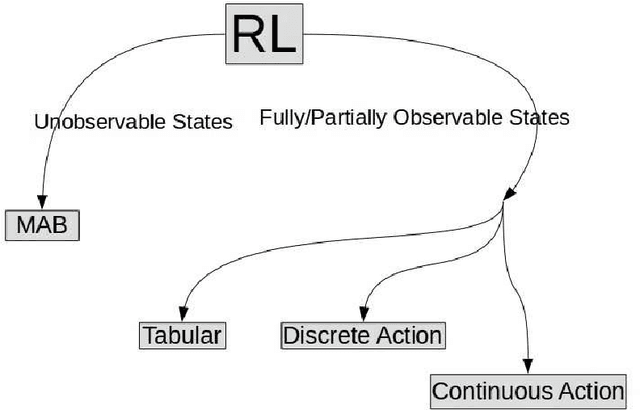
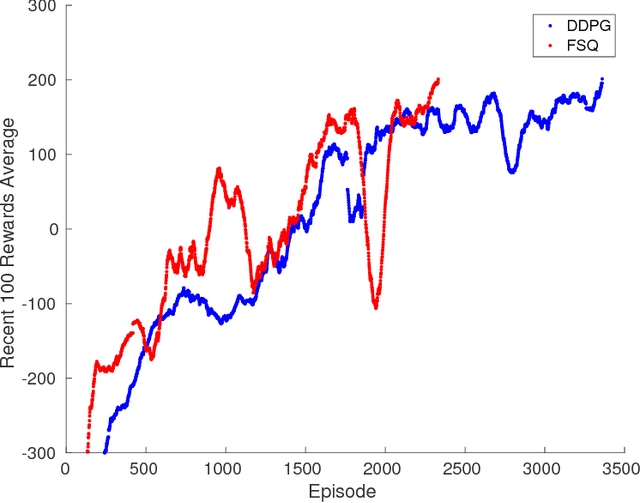
In this article, we sketch an algorithm that extends the Q-learning algorithms to the continuous action space domain. Our method is based on the discretization of the action space. Despite the commonly used discretization methods, our method does not increase the discretized problem dimensionality exponentially. We will show that our proposed method is linear in complexity when the discretization is employed. The variant of the Q-learning algorithm presented in this work, labeled as Finite Step Q-Learning (FSQ), can be deployed to both shallow and deep neural network architectures.
View paper on