 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Copula Diffusion
Paper and Code
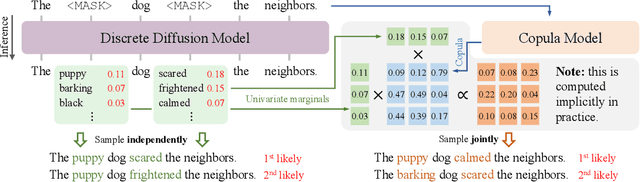
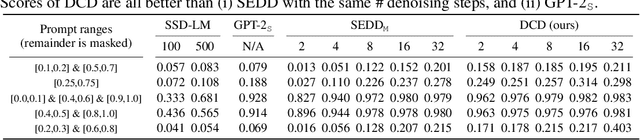


Discrete diffusion models have recently shown significant progress in modeling complex data, such as natural languages and DNA sequences. However, unlike diffusion models for continuous data, which can generate high-quality samples in just a few denoising steps, modern discrete diffusion models still require hundreds or even thousands of denoising steps to perform well. In this paper, we identify a fundamental limitation that prevents discrete diffusion models from achieving strong performance with fewer steps -- they fail to capture dependencies between output variables at each denoising step. To address this issue, we provide a formal explanation and introduce a general approach to supplement the missing dependency information by incorporating another deep generative model, termed the copula model. Our method does not require fine-tuning either the diffusion model or the copula model, yet it enables high-quality sample generation with significantly fewer denoising steps. When we apply this approach to autoregressive copula models, the combined model outperforms both models individually in unconditional and conditional text generation. Specifically, the hybrid model achieves better (un)conditional text generation using 8 to 32 times fewer denoising steps than the diffusion model alone. In addition to presenting an effective discrete diffusion generation algorithm, this paper emphasizes the importance of modeling inter-variable dependencies in discrete diffusion.