 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirichlet Pruning for Neural Network Compression
Paper and Code
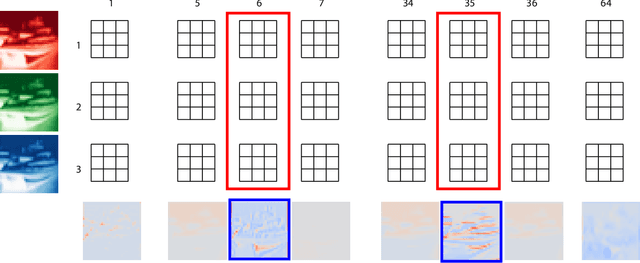
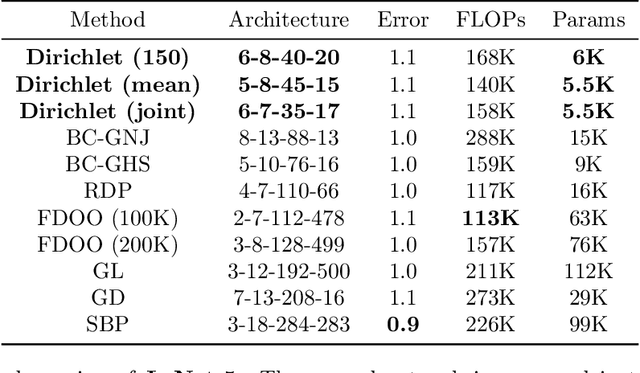
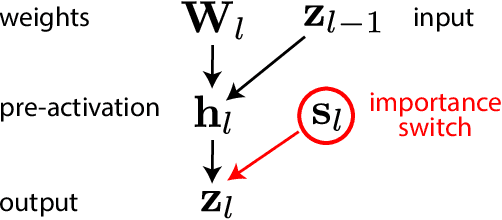

We introduce Dirichlet pruning, a novel post-processing technique to transform a large neural network model into a compressed one. Dirichlet pruning is a form of structured pruning which assigns the Dirichlet distribution over each layer's channels in convolutional layers (or neurons in fully-connected layers), and estimates the parameters of the distribution over these units using variational inference. The learned distribution allows us to remove unimportant units, resulting in a compact architecture containing only crucial features for a task at hand. Our method is extremely fast to train. The number of newly introduced Dirichlet parameters is only linear in the number of channels, which allows for rapid training, requiring as little as one epoch to converge. We perform extensive experiments, in particular on larger architectures such as VGG and WideResNet (45% and 52% compression rate, respectively) where our method achieves the state-of-the-art compression performance and provides interpretable features as a by-product.