 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirected Exploration for Reinforcement Learning
Paper and Code
Jun 18, 2019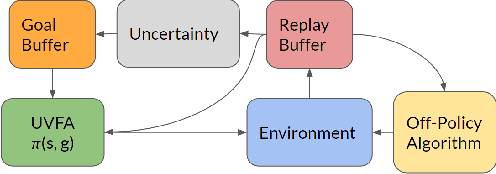
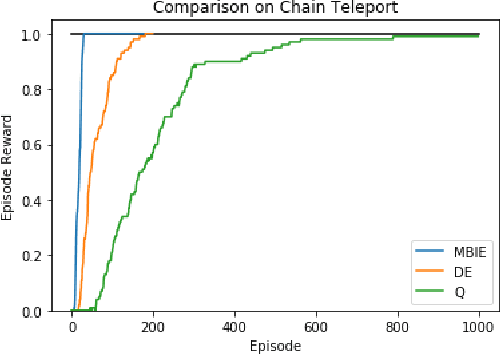
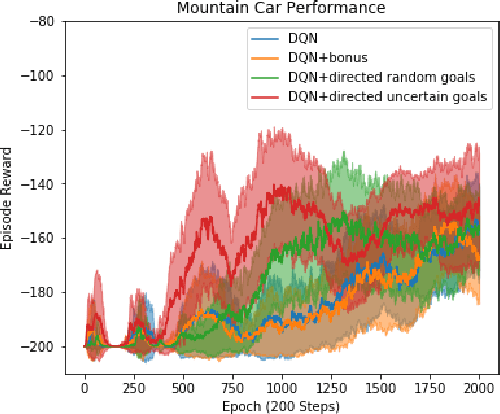
Efficient exploration is necessary to achieve good sample efficiency for reinforcement learning in general. From small, tabular settings such as gridworlds to large, continuous and sparse reward settings such as robotic object manipulation tasks, exploration through adding an uncertainty bonus to the reward function has been shown to be effective when the uncertainty is able to accurately drive exploration towards promising states. However reward bonuses can still be inefficient since they are non-stationary, which means that we must wait for function approximators to catch up and converge again when uncertainties change. We propose the idea of directed exploration, that is learning a goal-conditioned policy where goals are simply other states, and using that to directly try to reach states with large uncertainty. The goal-conditioned policy is independent of uncertainty and is thus stationary. We show in our experiments how directed exploration is more efficient at exploration and more robust to how the uncertainty is computed than adding bonuses to rewards.