 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduction for Sentiment Classification: Evolving for the Most Prominent and Separable Features
Paper and Code
Jun 01, 2020
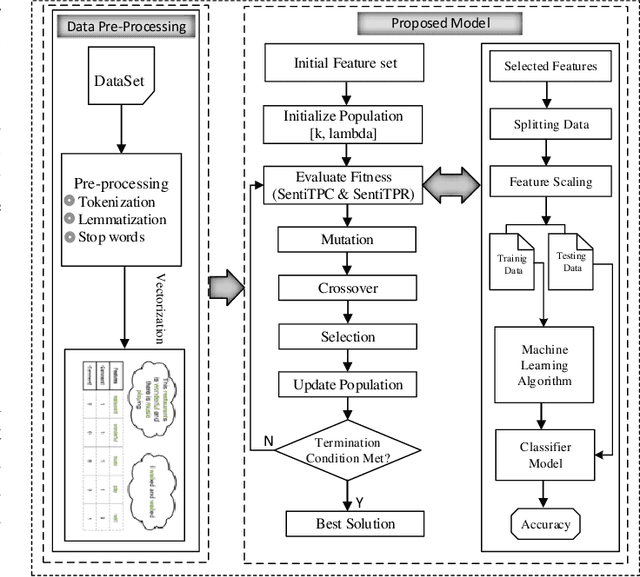
In sentiment classification, the enormous amount of textual data, its immense dimensionality, and inherent noise make it extremely difficult for machine learning classifiers to extract high-level and complex abstractions. In order to make the data less sparse and more statistically significant, the dimensionality reduction techniques are needed. But in the existing dimensionality reduction techniques, the number of components needs to be set manually which results in loss of the most prominent features, thus reducing the performance of the classifiers. Our prior work, i.e., Term Presence Count (TPC) and Term Presence Ratio (TPR) have proven to be effective techniques as they reject the less separable features. However, the most prominent and separable features might still get removed from the initial feature set despite having higher distributions among positive and negative tagged documents. To overcome this problem, we have proposed a new framework that consists of two-dimensionality reduction techniques i.e., Sentiment Term Presence Count (SentiTPC) and Sentiment Term Presence Ratio (SentiTPR). These techniques reject the features by considering term presence difference for SentiTPC and ratio of the distribution distinction for SentiTPR. Additionally, these methods also analyze the total distribution information. Extensive experimental results exhibit that the proposed framework reduces the feature dimension by a large scale, and thus significantly improve the classification performance.