 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduction and (Bucket) Ranking: a Mass Transportation Approach
Paper and Code
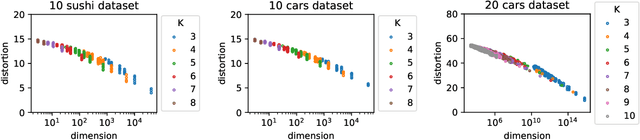
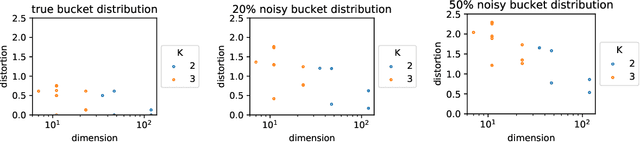
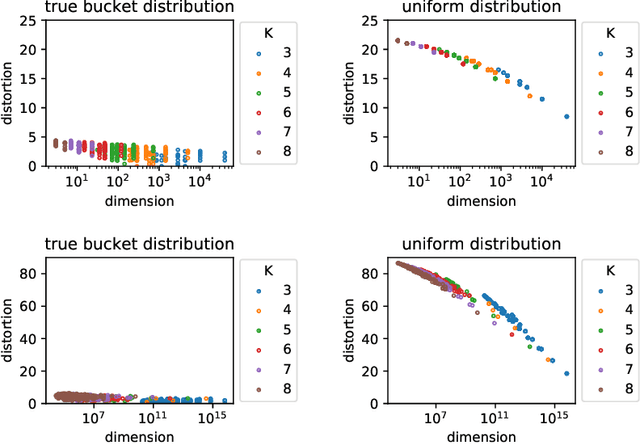
Whereas most dimensionality reduction techniques (e.g. PCA, ICA, NMF) for multivariate data essentially rely on linear algebra to a certain extent, summarizing ranking data, viewed as realizations of a random permutation $\Sigma$ on a set of items indexed by $i\in \{1,\ldots,\; n\}$, is a great statistical challenge, due to the absence of vector space structure for the set of permutations $\mathfrak{S}_n$. It is the goal of this article to develop an original framework for possibly reducing the number of parameters required to describe the distribution of a statistical population composed of rankings/permutations, on the premise that the collection of items under study can be partitioned into subsets/buckets, such that, with high probability, items in a certain bucket are either all ranked higher or else all ranked lower than items in another bucket. In this context, $\Sigma$'s distribution can be hopefully represented in a sparse manner by a bucket distribution, i.e. a bucket ordering plus the ranking distributions within each bucket. More precisely, we introduce a dedicated distortion measure, based on a mass transportation metric, in order to quantify the accuracy of such representations. The performance of buckets minimizing an empirical version of the distortion is investigated through a rate bound analysis. Complexity penalization techniques are also considered to select the shape of a bucket order with minimum expected distortion. Beyond theoretical concepts and results, numerical experiments on real ranking data are displayed in order to provide empirical evidence of the relevance of the approach promoted.