 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Socrates: Evaluating LLMs through explanation critiques
Paper and Code


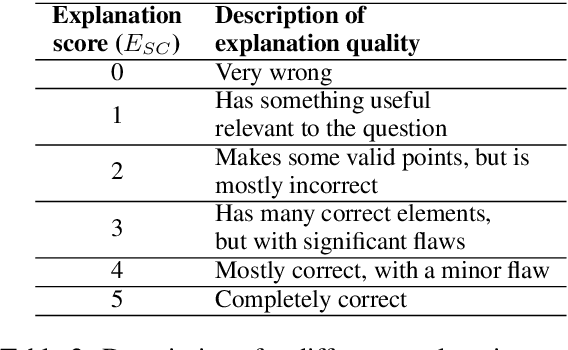
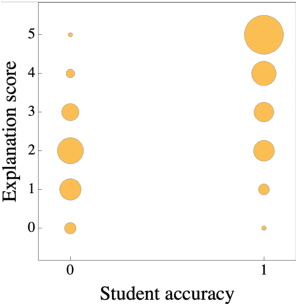
While LLMs can provide reasoned explanations along with their answers, the nature and quality of those explanations are still poorly understood. In response, our goal is to define a detailed way of characterizing the explanation capabilities of modern models and to create a nuanced, interpretable explanation evaluation tool that can generate such characterizations automatically, without relying on expensive API calls or human annotations. Our approach is to (a) define the new task of explanation critiquing - identifying and categorizing any main flaw in an explanation and providing suggestions to address the flaw, (b) create a sizeable, human-verified dataset for this task, and (c) train an open-source, automatic critiquing model (called Digital Socrates) using this data. Through quantitative and qualitative analysis, we demonstrate how Digital Socrates is useful for revealing insights about student models by examining their reasoning chains, and how it can provide high-quality, nuanced, automatic evaluation of those model explanations for the first time. Digital Socrates thus fills an important gap in evaluation tools for understanding and improving the explanation behavior of models.