 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Meets DAgger: Supercharging Eye-in-hand Imitation Learning
Paper and Code
Feb 27, 2024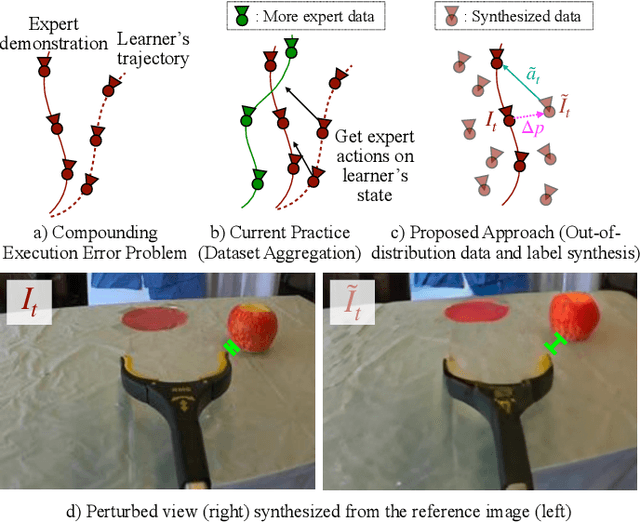

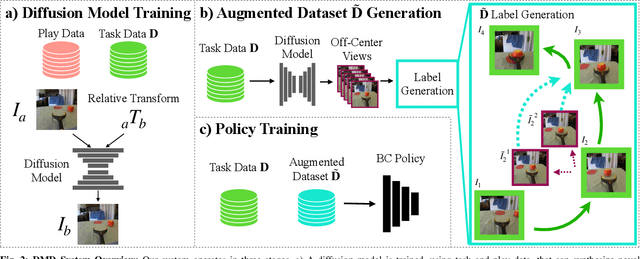
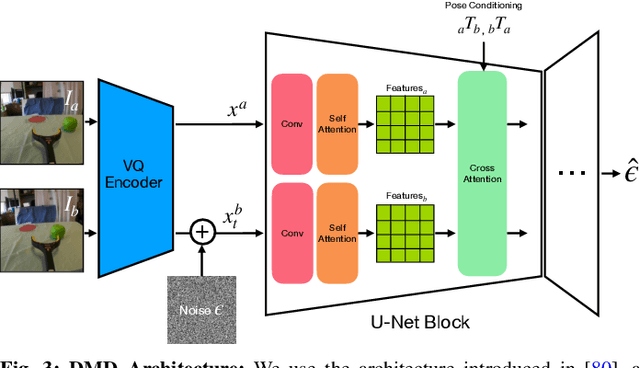
A common failure mode for policies trained with imitation is compounding execution errors at test time. When the learned policy encounters states that were not present in the expert demonstrations, the policy fails, leading to degenerate behavior. The Dataset Aggregation, or DAgger approach to this problem simply collects more data to cover these failure states. However, in practice, this is often prohibitively expensive. In this work, we propose Diffusion Meets DAgger (DMD), a method to reap the benefits of DAgger without the cost for eye-in-hand imitation learning problems. Instead of collecting new samples to cover out-of-distribution states, DMD uses recent advances in diffusion models to create these samples with diffusion models. This leads to robust performance from few demonstrations. In experiments conducted for non-prehensile pushing on a Franka Research 3, we show that DMD can achieve a success rate of 80% with as few as 8 expert demonstrations, where naive behavior cloning reaches only 20%. DMD also outperform competing NeRF-based augmentation schemes by 50%.