 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private SGD with Sparse Gradients
Paper and Code


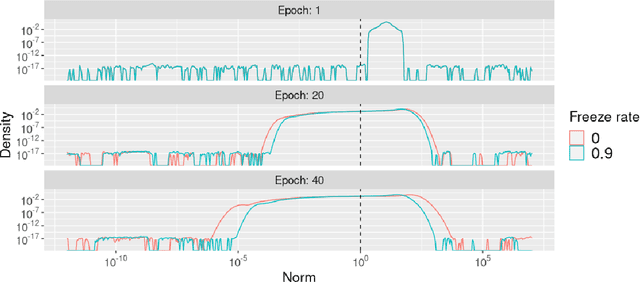

To protect sensitive training data, differentially private stochastic gradient descent (DP-SGD) has been adopted in deep learning to provide rigorously defined privacy. However, DP-SGD requires the injection of an amount of noise that scales with the number of gradient dimensions, resulting in large performance drops compared to non-private training. In this work, we propose random freeze which randomly freezes a progressively increasing subset of parameters and results in sparse gradient updates while maintaining or increasing accuracy. We theoretically prove the convergence of random freeze and find that random freeze exhibits a signal loss and perturbation moderation trade-off in DP-SGD. Applying random freeze across various DP-SGD frameworks, we maintain accuracy within the same number of iterations while achieving up to 70% representation sparsity, which demonstrates that the trade-off exists in a variety of DP-SGD methods. We further note that random freeze significantly improves accuracy, in particular for large networks. Additionally, axis-aligned sparsity induced by random freeze leads to various advantages for projected DP-SGD or federated learning in terms of computational cost, memory footprint and communication overhead.