 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private ERM Based on Data Perturbation
Paper and Code
Feb 20, 2020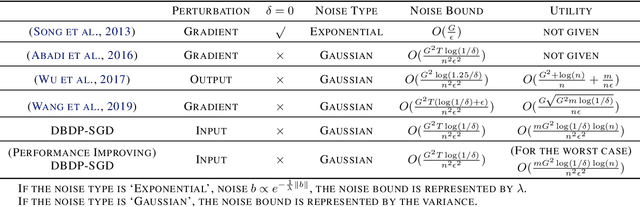
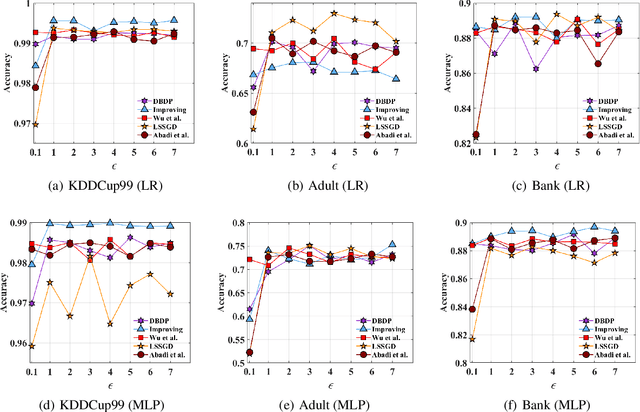

In this paper, after observing that different training data instances affect the machine learning model to different extents, we attempt to improve the performance of differentially private empirical risk minimization (DP-ERM) from a new perspective. Specifically, we measure the contributions of various training data instances on the final machine learning model, and select some of them to add random noise. Considering that the key of our method is to measure each data instance separately, we propose a new `Data perturbation' based (DB) paradigm for DP-ERM: adding random noise to the original training data and achieving ($\epsilon,\delta$)-differential privacy on the final machine learning model, along with the preservation on the original data. By introducing the Influence Function (IF), we quantitatively measure the impact of the training data on the final model. Theoretical and experimental results show that our proposed DBDP-ERM paradigm enhances the model performance significantly.