 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Deep Learning with Direct Feedback Alignment
Paper and Code
Oct 08, 2020
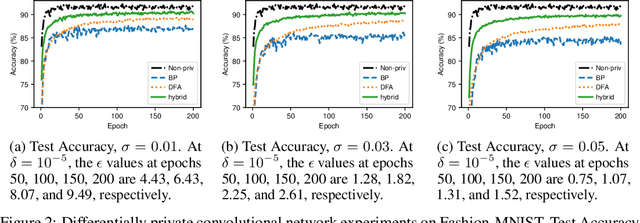
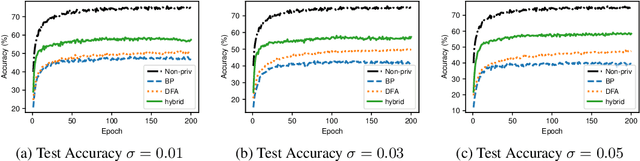

Standard methods for differentially private training of deep neural networks replace back-propagated mini-batch gradients with biased and noisy approximations to the gradient. These modifications to training often result in a privacy-preserving model that is significantly less accurate than its non-private counterpart. We hypothesize that alternative training algorithms may be more amenable to differential privacy. Specifically, we examine the suitability of direct feedback alignment (DFA). We propose the first differentially private method for training deep neural networks with DFA and show that it achieves significant gains in accuracy (often by 10-20%) compared to backprop-based differentially private training on a variety of architectures (fully connected, convolutional) and datasets.