 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevil is in Channels: Contrastive Single Domain Generalization for Medical Image Segmentation
Paper and Code
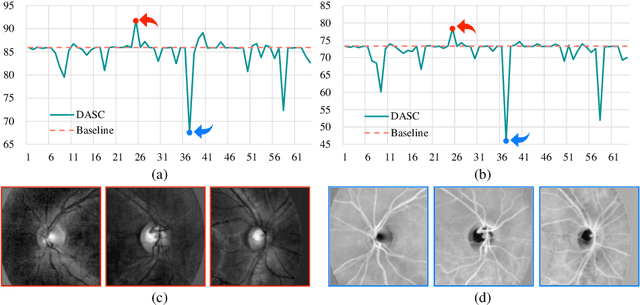
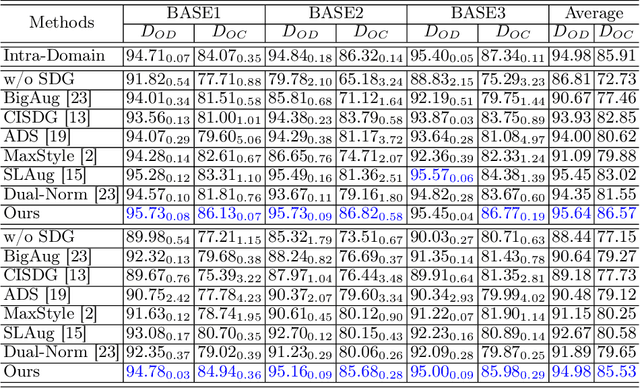
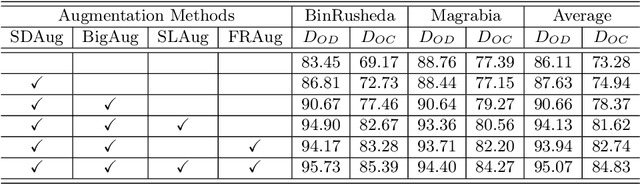
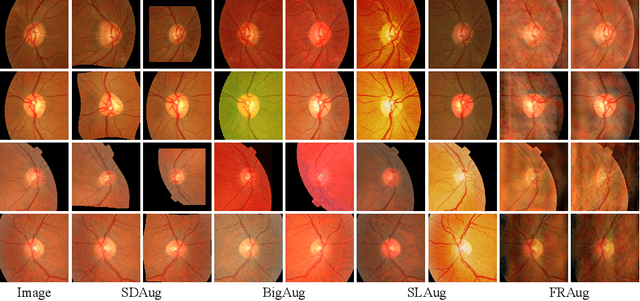
Deep learning-based medical image segmentation models suffer from performance degradation when deployed to a new healthcare center. To address this issue, unsupervised domain adaptation and multi-source domain generalization methods have been proposed, which, however, are less favorable for clinical practice due to the cost of acquiring target-domain data and the privacy concerns associated with redistributing the data from multiple source domains. In this paper, we propose a \textbf{C}hannel-level \textbf{C}ontrastive \textbf{S}ingle \textbf{D}omain \textbf{G}eneralization (\textbf{C$^2$SDG}) model for medical image segmentation. In C$^2$SDG, the shallower features of each image and its style-augmented counterpart are extracted and used for contrastive training, resulting in the disentangled style representations and structure representations. The segmentation is performed based solely on the structure representations. Our method is novel in the contrastive perspective that enables channel-wise feature disentanglement using a single source domain. We evaluated C$^2$SDG against six SDG methods on a multi-domain joint optic cup and optic disc segmentation benchmark. Our results suggest the effectiveness of each module in C$^2$SDG and also indicate that C$^2$SDG outperforms the baseline and all competing methods with a large margin. The code will be available at \url{https://github.com/ShishuaiHu/CCSDG}.