 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Initialization of the K-Means Algorithm Using Hierarchical Clustering
Paper and Code
Apr 28, 2013
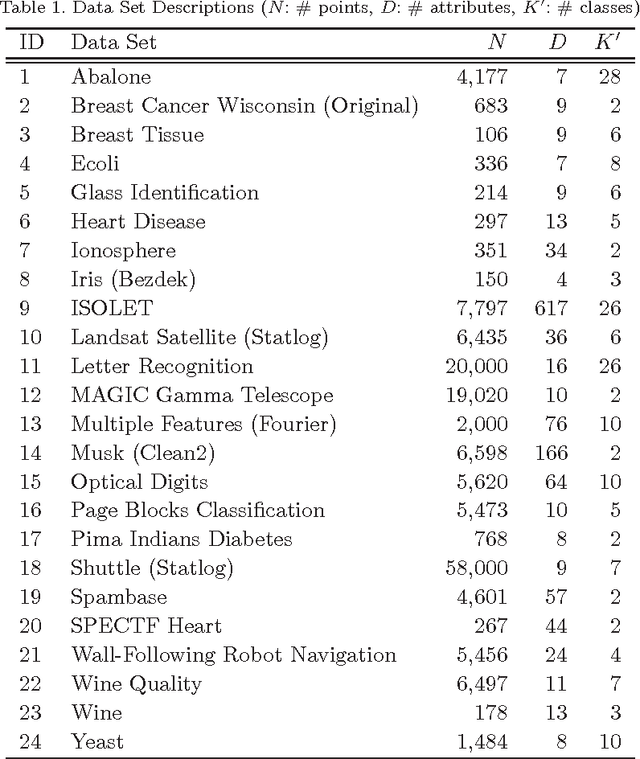

K-means is undoubtedly the most widely used partitional clustering algorithm. Unfortunately, due to its gradient descent nature, this algorithm is highly sensitive to the initial placement of the cluster centers. Numerous initialization methods have been proposed to address this problem. Many of these methods, however, have superlinear complexity in the number of data points, making them impractical for large data sets. On the other hand, linear methods are often random and/or order-sensitive, which renders their results unrepeatable. Recently, Su and Dy proposed two highly successful hierarchical initialization methods named Var-Part and PCA-Part that are not only linear, but also deterministic (non-random) and order-invariant. In this paper, we propose a discriminant analysis based approach that addresses a common deficiency of these two methods. Experiments on a large and diverse collection of data sets from the UCI Machine Learning Repository demonstrate that Var-Part and PCA-Part are highly competitive with one of the best random initialization methods to date, i.e., k-means++, and that the proposed approach significantly improves the performance of both hierarchical methods.