 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Violence in Video using Subclasses
Paper and Code
Apr 27, 2016
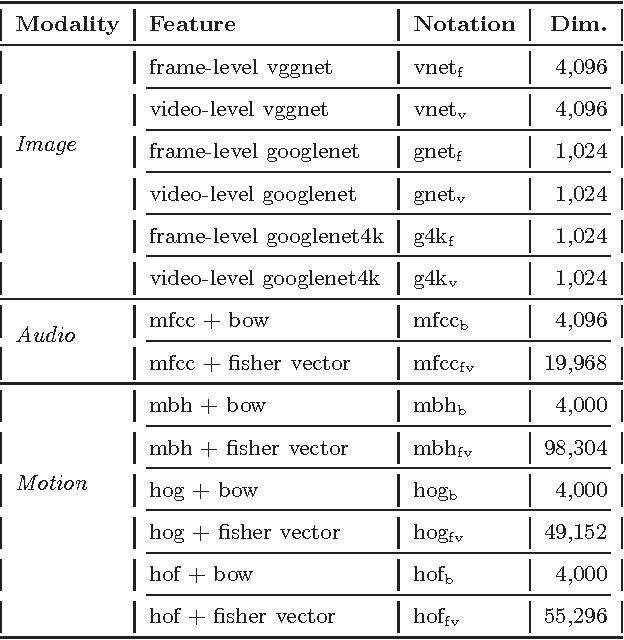
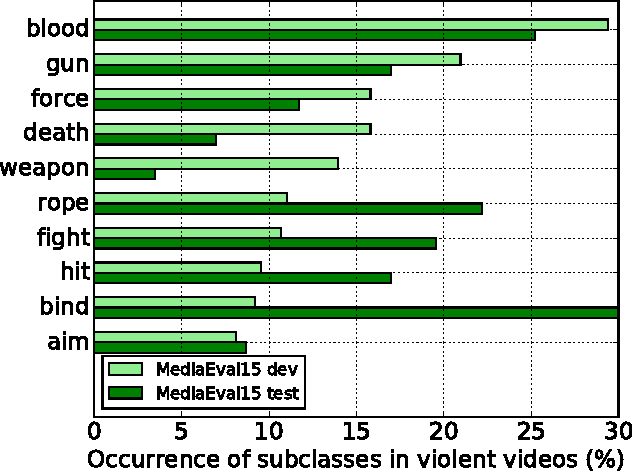
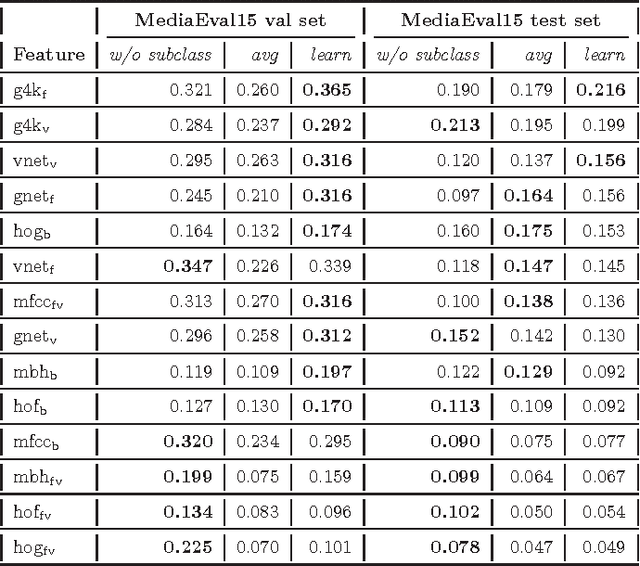
This paper attacks the challenging problem of violence detection in videos. Different from existing works focusing on combining multi-modal features, we go one step further by adding and exploiting subclasses visually related to violence. We enrich the MediaEval 2015 violence dataset by \emph{manually} labeling violence videos with respect to the subclasses. Such fine-grained annotations not only help understand what have impeded previous efforts on learning to fuse the multi-modal features, but also enhance the generalization ability of the learned fusion to novel test data. The new subclass based solution, with AP of 0.303 and P100 of 0.55 on the MediaEval 2015 test set, outperforms several state-of-the-art alternatives. Notice that our solution does not require fine-grained annotations on the test set, so it can be directly applied on novel and fully unlabeled videos. Interestingly, our study shows that motion related features, though being essential part in previous systems, are dispensable.