 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing Common Human Visual Actions in Images
Paper and Code
Jun 07, 2015
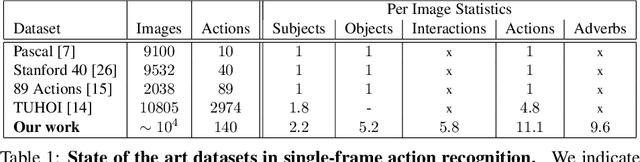
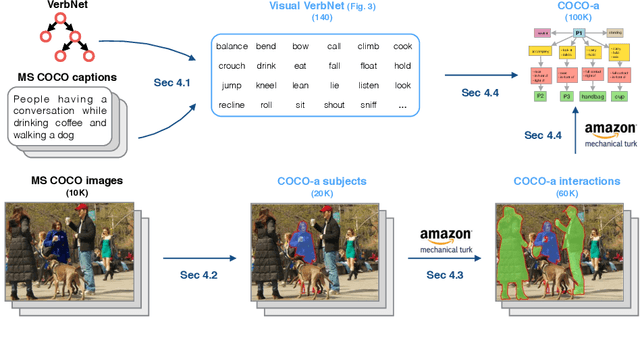
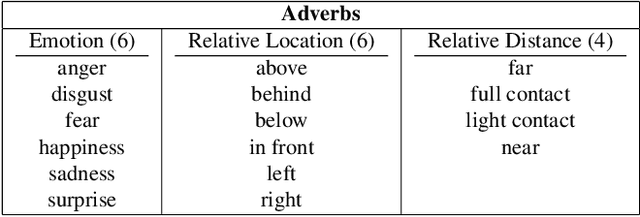
Which common human actions and interactions are recognizable in monocular still images? Which involve objects and/or other people? How many is a person performing at a time? We address these questions by exploring the actions and interactions that are detectable in the images of the MS COCO dataset. We make two main contributions. First, a list of 140 common `visual actions', obtained by analyzing the largest on-line verb lexicon currently available for English (VerbNet) and human sentences used to describe images in MS COCO. Second, a complete set of annotations for those `visual actions', composed of subject-object and associated verb, which we call COCO-a (a for `actions'). COCO-a is larger than existing action datasets in terms of number of actions and instances of these actions, and is unique because it is data-driven, rather than experimenter-biased. Other unique features are that it is exhaustive, and that all subjects and objects are localized. A statistical analysis of the accuracy of our annotations and of each action, interaction and subject-object combination is provided.