 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing and Understanding Neighborhood Characteristics through Online Social Media
Paper and Code
Mar 11, 2015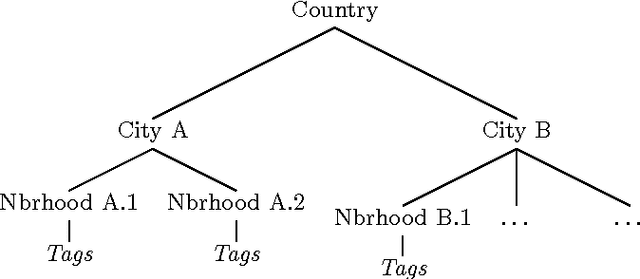

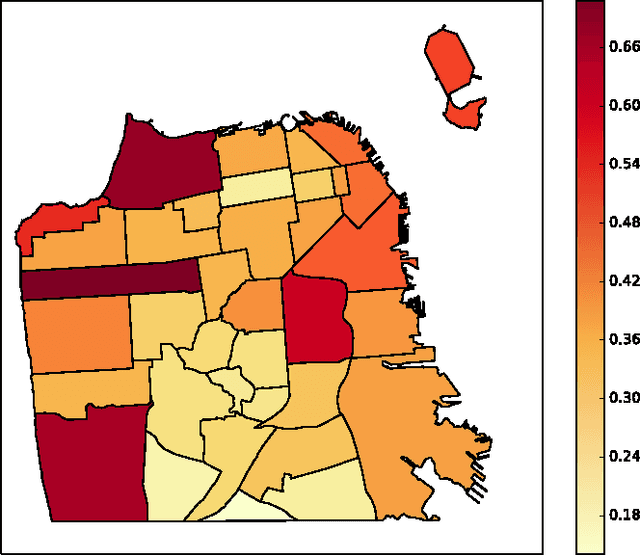

Geotagged data can be used to describe regions in the world and discover local themes. However, not all data produced within a region is necessarily specifically descriptive of that area. To surface the content that is characteristic for a region, we present the geographical hierarchy model (GHM), a probabilistic model based on the assumption that data observed in a region is a random mixture of content that pertains to different levels of a hierarchy. We apply the GHM to a dataset of 8 million Flickr photos in order to discriminate between content (i.e., tags) that specifically characterizes a region (e.g., neighborhood) and content that characterizes surrounding areas or more general themes. Knowledge of the discriminative and non-discriminative terms used throughout the hierarchy enables us to quantify the uniqueness of a given region and to compare similar but distant regions. Our evaluation demonstrates that our model improves upon traditional Naive Bayes classification by 47% and hierarchical TF-IDF by 27%. We further highlight the differences and commonalities with human reasoning about what is locally characteristic for a neighborhood, distilled from ten interviews and a survey that covered themes such as time, events, and prior regional knowledge