 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthwise Convolution for Multi-Agent Communication with Enhanced Mean-Field Approximation
Paper and Code
Mar 06, 2022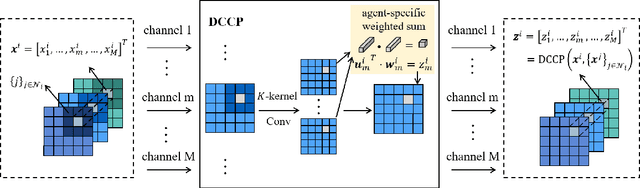



Multi-agent settings remain a fundamental challenge in the reinforcement learning (RL) domain due to the partial observability and the lack of accurate real-time interactions across agents. In this paper, we propose a new method based on local communication learning to tackle the multi-agent RL (MARL) challenge within a large number of agents coexisting. First, we design a new communication protocol that exploits the ability of depthwise convolution to efficiently extract local relations and learn local communication between neighboring agents. To facilitate multi-agent coordination, we explicitly learn the effect of joint actions by taking the policies of neighboring agents as inputs. Second, we introduce the mean-field approximation into our method to reduce the scale of agent interactions. To more effectively coordinate behaviors of neighboring agents, we enhance the mean-field approximation by a supervised policy rectification network (PRN) for rectifying real-time agent interactions and by a learnable compensation term for correcting the approximation bias. The proposed method enables efficient coordination as well as outperforms several baseline approaches on the adaptive traffic signal control (ATSC) task and the StarCraft II multi-agent challenge (SMAC).