 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseImage Network: Video Spatial-Temporal Evolution Encoding and Understanding
Paper and Code


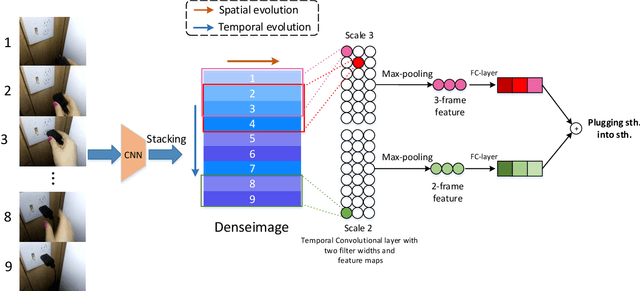

Many of the leading approaches for video understanding are data-hungry and time-consuming, failing to capture the gist of spatial-temporal evolution in an efficient manner. The latest research shows that CNN network can reason about static relation of entities in images. To further exploit its capacity in dynamic evolution reasoning, we introduce a novel network module called DenseImage Network(DIN) with two main contributions. 1) A novel compact representation of video which distills its significant spatial-temporal evolution into a matrix called DenseImage, primed for efficient video encoding. 2) A simple yet powerful learning strategy based on DenseImage and a temporal-order-preserving CNN network is proposed for video understanding, which contains a local temporal correlation constraint capturing temporal evolution at multiple time scales with different filter widths. Extensive experiments on two recent challenging benchmarks demonstrate that our DenseImage Network can accurately capture the common spatial-temporal evolution between similar actions, even with enormous visual variations or different time scales. Moreover, we obtain the state-of-the-art results in action and gesture recognition with much less time-and-memory cost, indicating its immense potential in video representing and understanding.