 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegrees of freedom for off-the-grid sparse estimation
Paper and Code
Nov 08, 2019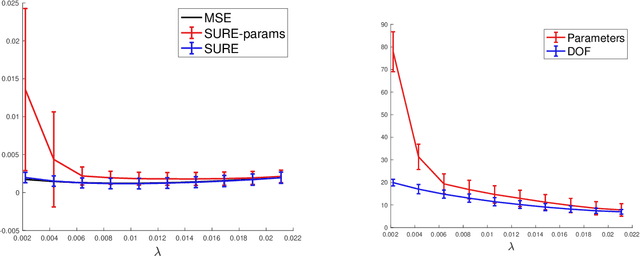
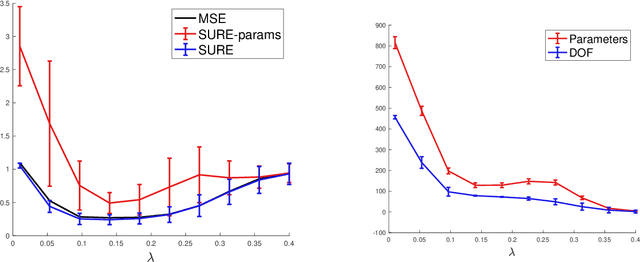
A central question in modern machine learning and imaging sciences is to quantify the number of effective parameters of vastly over-parameterized models. The degrees of freedom is a mathematically convenient way to define this number of parameters. Its computation and properties are well understood when dealing with discretized linear models, possibly regularized using sparsity. In this paper, we argue that this way of thinking is plagued when dealing with models having very large parameter spaces. In this case it makes more sense to consider "off-the-grid" approaches, using a continuous parameter space. This type of approach is the one favoured when training multi-layer perceptrons, and is also becoming popular to solve super-resolution problems in imaging. Training these off-the-grid models with a sparsity inducing prior can be achieved by solving a convex optimization problem over the space of measures, which is often called the Beurling Lasso (Blasso), and is the continuous counterpart of the celebrated Lasso parameter selection method. In previous works, the degrees of freedom for the Lasso was shown to coincide with the size of the smallest solution support. Our main contribution is a proof of a continuous counterpart to this result for the Blasso. Our findings suggest that discretized methods actually vastly over-estimate the number of intrinsic continuous degrees of freedom. Our second contribution is a detailed study of the case of sampling Fourier coefficients in 1D, which corresponds to a super-resolution problem. We show that our formula for the degrees of freedom is valid outside of a set of measure zero of observations, which in turn justifies its use to compute an unbiased estimator of the prediction risk using the Stein Unbiased Risk Estimator (SURE).