 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Against Adversarial Attacks by Leveraging an Entire GAN
Paper and Code
May 27, 2018
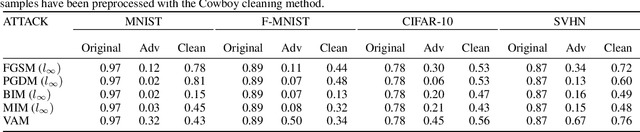

Recent work has shown that state-of-the-art models are highly vulnerable to adversarial perturbations of the input. We propose cowboy, an approach to detecting and defending against adversarial attacks by using both the discriminator and generator of a GAN trained on the same dataset. We show that the discriminator consistently scores the adversarial samples lower than the real samples across multiple attacks and datasets. We provide empirical evidence that adversarial samples lie outside of the data manifold learned by the GAN. Based on this, we propose a cleaning method which uses both the discriminator and generator of the GAN to project the samples back onto the data manifold. This cleaning procedure is independent of the classifier and type of attack and thus can be deployed in existing systems.