 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTrack: Learning Discriminative Feature Representations Online for Robust Visual Tracking
Paper and Code
Feb 28, 2015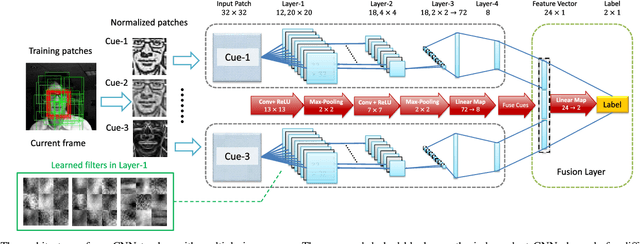
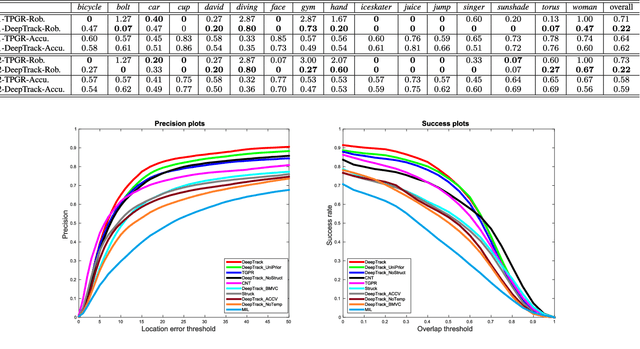
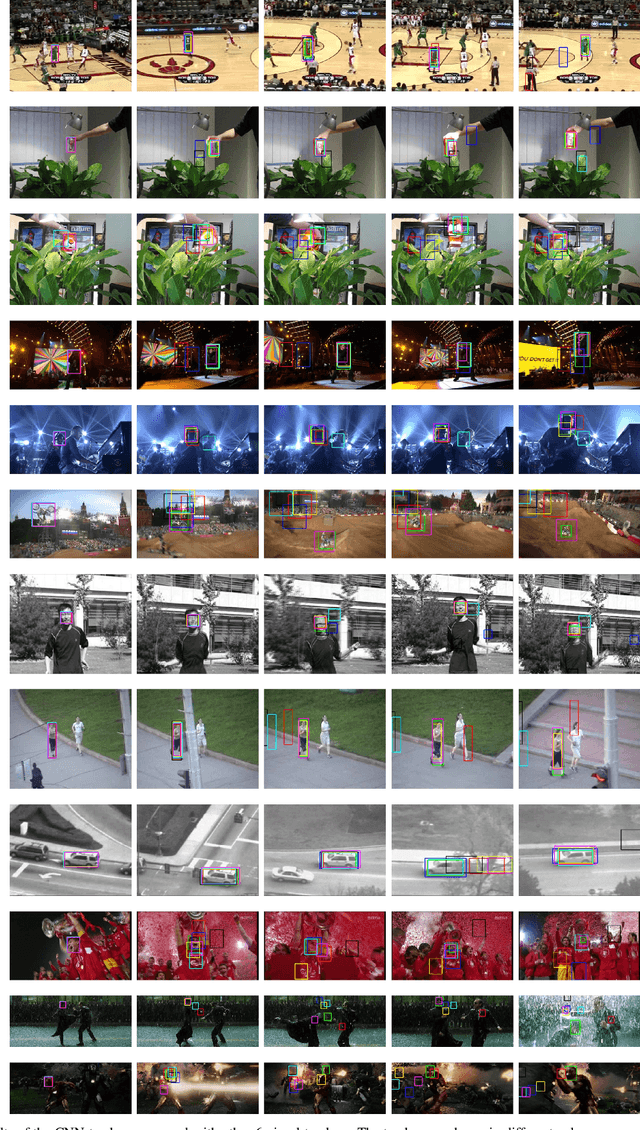

Deep neural networks, albeit their great success on feature learning in various computer vision tasks, are usually considered as impractical for online visual tracking because they require very long training time and a large number of training samples. In this work, we present an efficient and very robust tracking algorithm using a single Convolutional Neural Network (CNN) for learning effective feature representations of the target object, in a purely online manner. Our contributions are multifold: First, we introduce a novel truncated structural loss function that maintains as many training samples as possible and reduces the risk of tracking error accumulation. Second, we enhance the ordinary Stochastic Gradient Descent approach in CNN training with a robust sample selection mechanism. The sampling mechanism randomly generates positive and negative samples from different temporal distributions, which are generated by taking the temporal relations and label noise into account. Finally, a lazy yet effective updating scheme is designed for CNN training. Equipped with this novel updating algorithm, the CNN model is robust to some long-existing difficulties in visual tracking such as occlusion or incorrect detections, without loss of the effective adaption for significant appearance changes. In the experiment, our CNN tracker outperforms all compared state-of-the-art methods on two recently proposed benchmarks which in total involve over 60 video sequences. The remarkable performance improvement over the existing trackers illustrates the superiority of the feature representations which are learned