Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepStance at SemEval-2016 Task 6: Detecting Stance in Tweets Using Character and Word-Level CNNs
Paper and Code
Jun 17, 2016

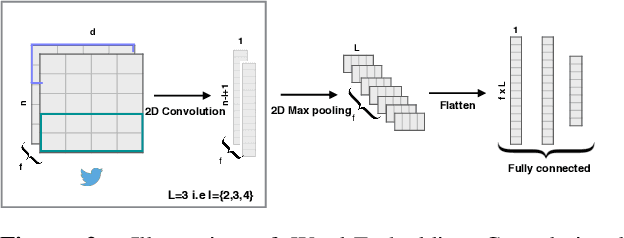

This paper describes our approach for the Detecting Stance in Tweets task (SemEval-2016 Task 6). We utilized recent advances in short text categorization using deep learning to create word-level and character-level models. The choice between word-level and character-level models in each particular case was informed through validation performance. Our final system is a combination of classifiers using word-level or character-level models. We also employed novel data augmentation techniques to expand and diversify our training dataset, thus making our system more robust. Our system achieved a macro-average precision, recall and F1-scores of 0.67, 0.61 and 0.635 respectively.
* SemEval 2016, San Diego, California. In Proceedings of the 10th
International Workshop on Semantic Evaluation (SemEval-2016). San Diego,
California
View paper on