 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepRebirth: Accelerating Deep Neural Network Execution on Mobile Devices
Paper and Code
Jan 10, 2018

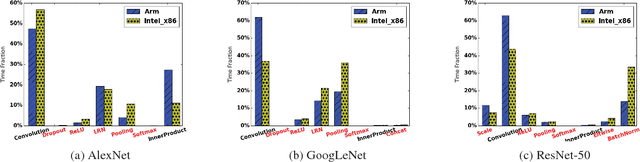

Deploying deep neural networks on mobile devices is a challenging task. Current model compression methods such as matrix decomposition effectively reduce the deployed model size, but still cannot satisfy real-time processing requirement. This paper first discovers that the major obstacle is the excessive execution time of non-tensor layers such as pooling and normalization without tensor-like trainable parameters. This motivates us to design a novel acceleration framework: DeepRebirth through "slimming" existing consecutive and parallel non-tensor and tensor layers. The layer slimming is executed at different substructures: (a) streamline slimming by merging the consecutive non-tensor and tensor layer vertically; (b) branch slimming by merging non-tensor and tensor branches horizontally. The proposed optimization operations significantly accelerate the model execution and also greatly reduce the run-time memory cost since the slimmed model architecture contains less hidden layers. To maximally avoid accuracy loss, the parameters in new generated layers are learned with layer-wise fine-tuning based on both theoretical analysis and empirical verification. As observed in the experiment, DeepRebirth achieves more than 3x speed-up and 2.5x run-time memory saving on GoogLeNet with only 0.4% drop of top-5 accuracy on ImageNet. Furthermore, by combining with other model compression techniques, DeepRebirth offers an average of 65ms inference time on the CPU of Samsung Galaxy S6 with 86.5% top-5 accuracy, 14% faster than SqueezeNet which only has a top-5 accuracy of 80.5%.