 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPoison: Feature Transfer Based Stealthy Poisoning Attack
Paper and Code
Jan 08, 2021
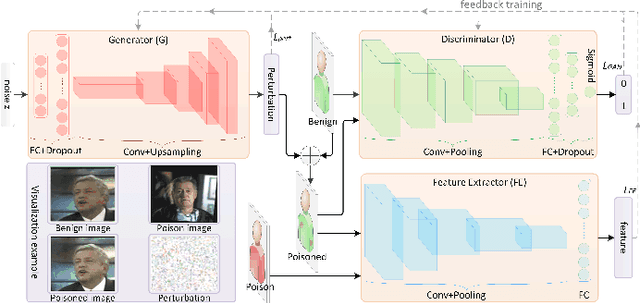
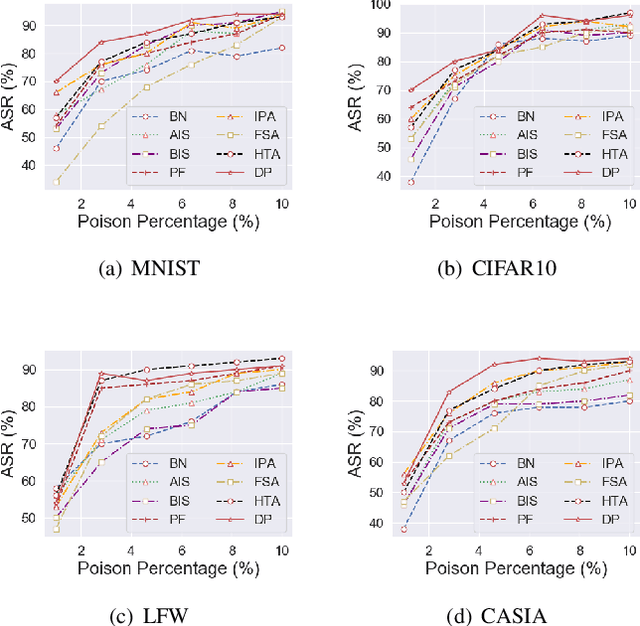
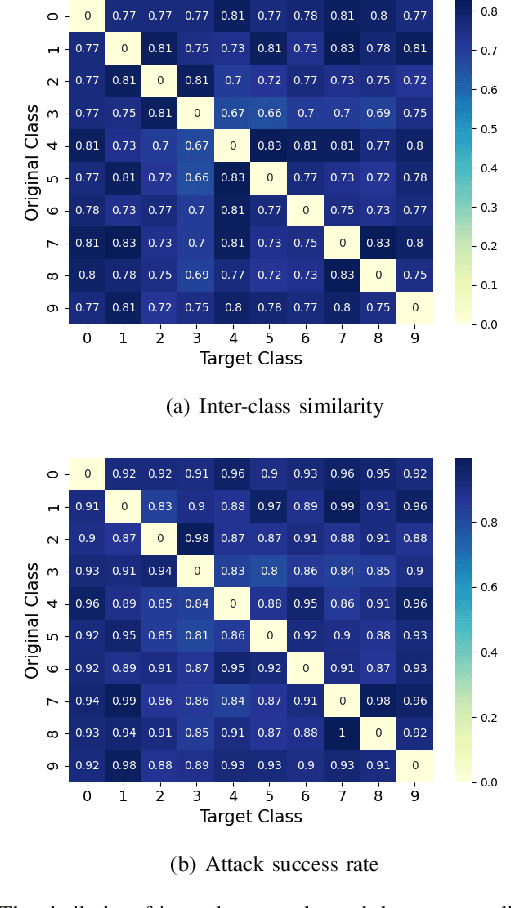
Deep neural networks are susceptible to poisoning attacks by purposely polluted training data with specific triggers. As existing episodes mainly focused on attack success rate with patch-based samples, defense algorithms can easily detect these poisoning samples. We propose DeepPoison, a novel adversarial network of one generator and two discriminators, to address this problem. Specifically, the generator automatically extracts the target class' hidden features and embeds them into benign training samples. One discriminator controls the ratio of the poisoning perturbation. The other discriminator works as the target model to testify the poisoning effects. The novelty of DeepPoison lies in that the generated poisoned training samples are indistinguishable from the benign ones by both defensive methods and manual visual inspection, and even benign test samples can achieve the attack. Extensive experiments have shown that DeepPoison can achieve a state-of-the-art attack success rate, as high as 91.74%, with only 7% poisoned samples on publicly available datasets LFW and CASIA. Furthermore, we have experimented with high-performance defense algorithms such as autodecoder defense and DBSCAN cluster detection and showed the resilience of DeepPoison.