 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMoM: Robust Deep Learning With Median-of-Means
Paper and Code
May 28, 2021
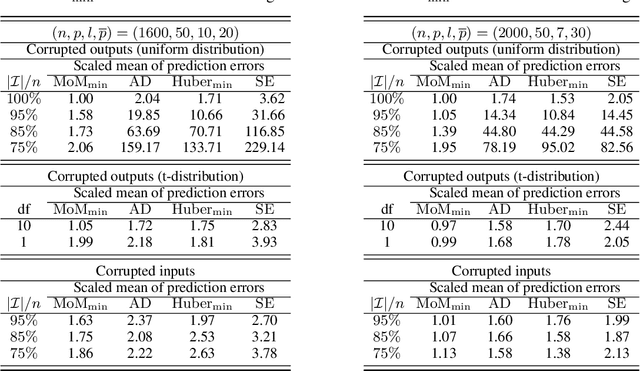
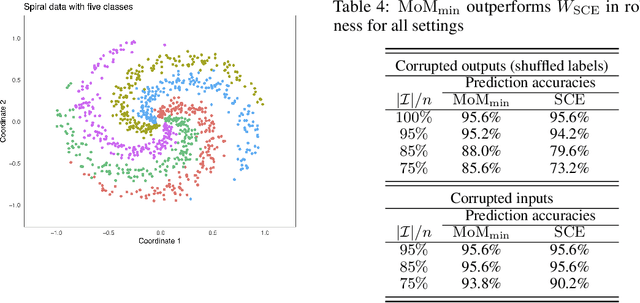

Data used in deep learning is notoriously problematic. For example, data are usually combined from diverse sources, rarely cleaned and vetted thoroughly, and sometimes corrupted on purpose. Intentional corruption that targets the weak spots of algorithms has been studied extensively under the label of "adversarial attacks." In contrast, the arguably much more common case of corruption that reflects the limited quality of data has been studied much less. Such "random" corruptions are due to measurement errors, unreliable sources, convenience sampling, and so forth. These kinds of corruption are common in deep learning, because data are rarely collected according to strict protocols -- in strong contrast to the formalized data collection in some parts of classical statistics. This paper concerns such corruption. We introduce an approach motivated by very recent insights into median-of-means and Le Cam's principle, we show that the approach can be readily implemented, and we demonstrate that it performs very well in practice. In conclusion, we believe that our approach is a very promising alternative to standard parameter training based on least-squares and cross-entropy loss.