 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfakes Generation and Detection: State-of-the-art, open challenges, countermeasures, and way forward
Paper and Code
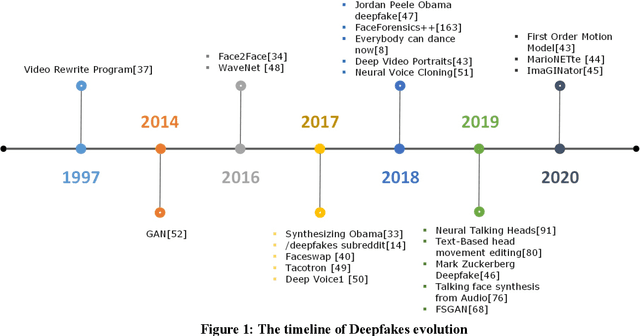
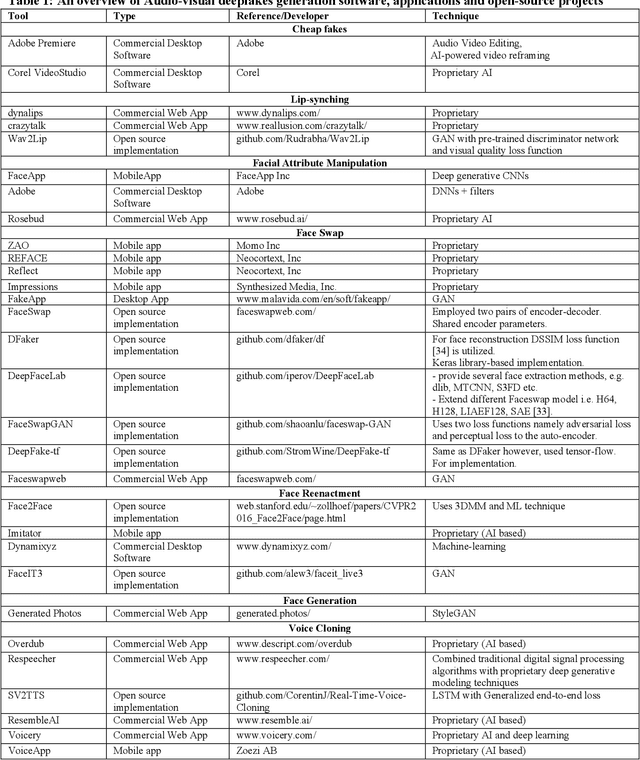

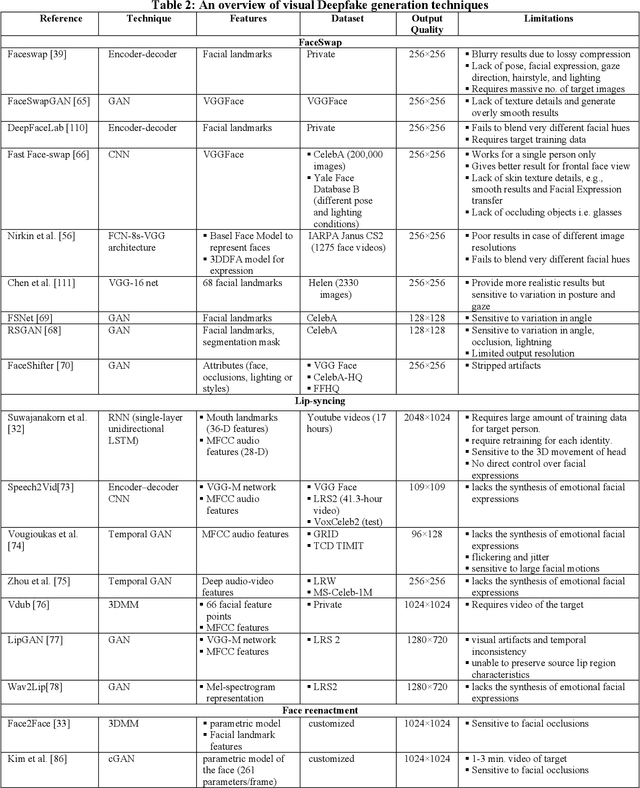
Easy access to audio-visual content on social media, combined with the availability of modern tools such as Tensorflow or Keras, open-source trained models, and economical computing infrastructure, and the rapid evolution of deep-learning (DL) methods, especially Generative Adversarial Networks (GAN), have made it possible to generate deepfakes to disseminate disinformation, revenge porn, financial frauds, hoaxes, and to disrupt government functioning. The existing surveys have mainly focused on deepfake video detection only. No attempt has been made to review approaches for detection and generation of both audio and video deepfakes. This paper provides a comprehensive review and detailed analysis of existing tools and machine learning (ML) based approaches for deepfake generation and the methodologies used to detect such manipulations for the detection and generation of both audio and video deepfakes. For each category of deepfake, we discuss information related to manipulation approaches, current public datasets, and key standards for the performance evaluation of deepfake detection techniques along with their results. Additionally, we also discuss open challenges and enumerate future directions to guide future researchers on issues that need to be considered to improve the domains of both the deepfake generation and detection. This work is expected to assist the readers in understanding the creation and detection mechanisms of deepfake, along with their current limitations and future direction.