Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeper & Sparser Exploration
Paper and Code
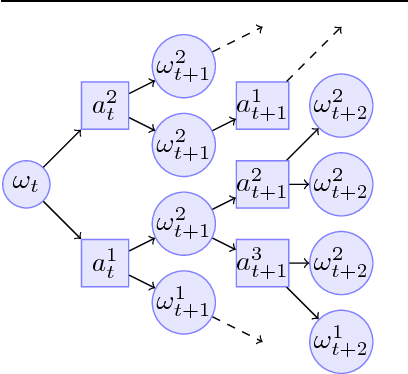

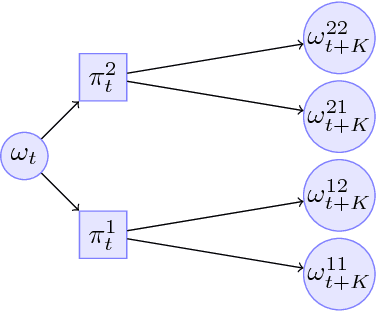
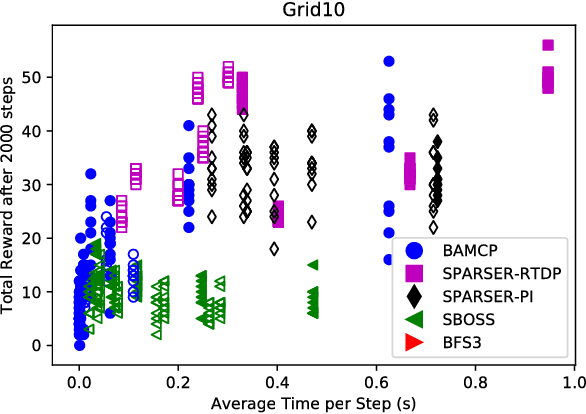
We address the problem of efficient exploration by proposing a new meta algorithm in the context of model-based online planning for Bayesian Reinforcement Learning (BRL). We beat the state-of-the-art, while staying computationally faster, in some cases by two orders of magnitude. This is the first Optimism free BRL algorithm to beat all previous state-of-the-art in tabular RL. The main novelty is the use of a candidate policy generator, to generate long-term options in the belief tree, which allows us to create much sparser and deeper trees. We present results on many standard environments and empirically prove its performance.
View paper on