 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Structure Inference Network for Facial Action Unit Recognition
Paper and Code
Mar 23, 2018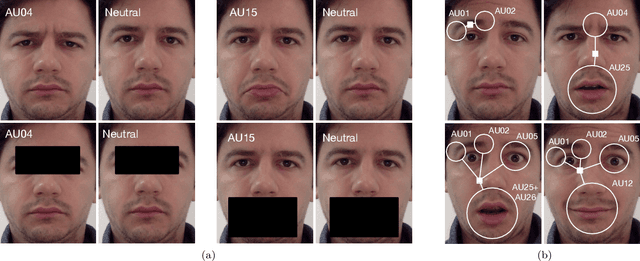
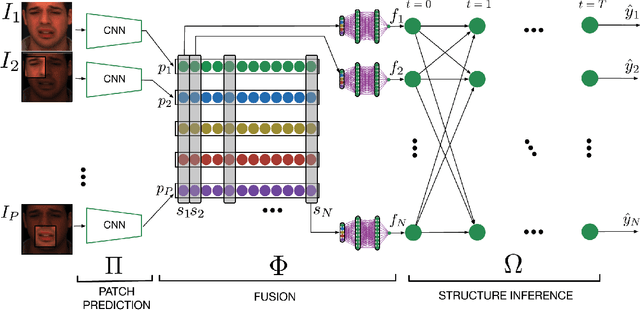
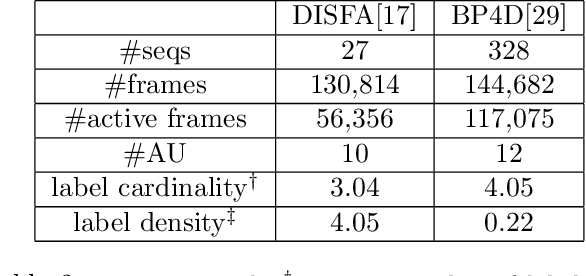
Facial expressions are combinations of basic components called Action Units (AU). Recognizing AUs is key for developing general facial expression analysis. In recent years, most efforts in automatic AU recognition have been dedicated to learning combinations of local features and to exploiting correlations between Action Units. In this paper, we propose a deep neural architecture that tackles both problems by combining learned local and global features in its initial stages and replicating a message passing algorithm between classes similar to a graphical model inference approach in later stages. We show that by training the model end-to-end with increased supervision we improve state-of-the-art by 5.3% and 8.2% performance on BP4D and DISFA datasets, respectively.