 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Structure for end-to-end inverse rendering
Paper and Code
Aug 25, 2017
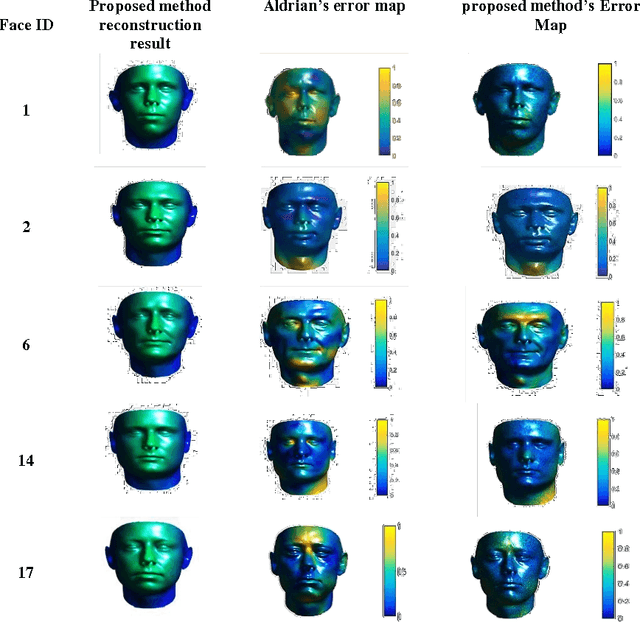
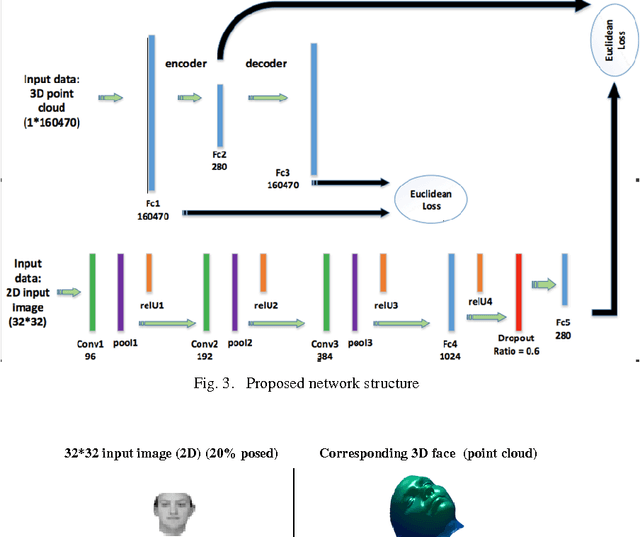

Inverse rendering in a 3D format denoted to recovering the 3D properties of a scene given 2D input image(s) and is typically done using 3D Morphable Model (3DMM) based methods from single view images. These models formulate each face as a weighted combination of some basis vectors extracted from the training data. In this paper a deep framework is proposed in which the coefficients and basis vectors are computed by training an autoencoder network and a Convolutional Neural Network (CNN) simultaneously. The idea is to find a common cause which can be mapped to both the 3D structure and corresponding 2D image using deep networks. The empirical results verify the power of deep framework in finding accurate 3D shapes of human faces from their corresponding 2D images on synthetic datasets of human faces.