 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Traveling Purchaser Problems
Paper and Code
Apr 11, 2024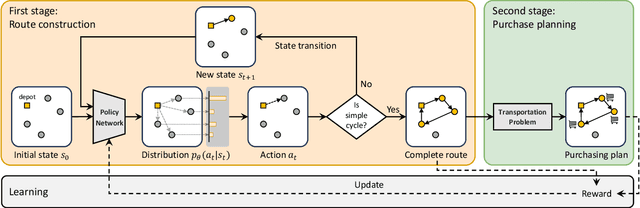
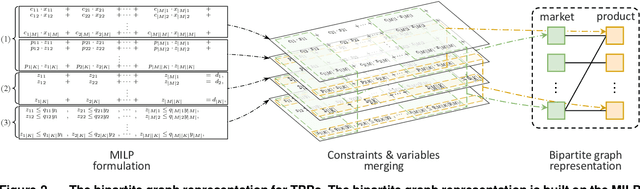
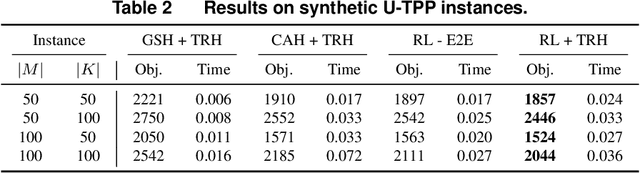
The traveling purchaser problem (TPP) is an important combinatorial optimization problem with broad applications. Due to the coupling between routing and purchasing, existing works on TPPs commonly address route construction and purchase planning simultaneously, which, however, leads to exact methods with high computational cost and heuristics with sophisticated design but limited performance. In sharp contrast, we propose a novel approach based on deep reinforcement learning (DRL), which addresses route construction and purchase planning separately, while evaluating and optimizing the solution from a global perspective. The key components of our approach include a bipartite graph representation for TPPs to capture the market-product relations, and a policy network that extracts information from the bipartite graph and uses it to sequentially construct the route. One significant benefit of our framework is that we can efficiently construct the route using the policy network, and once the route is determined, the associated purchasing plan can be easily derived through linear programming, while, leveraging DRL, we can train the policy network to optimize the global solution objective. Furthermore, by introducing a meta-learning strategy, the policy network can be trained stably on large-sized TPP instances, and generalize well across instances of varying sizes and distributions, even to much larger instances that are never seen during training. Experiments on various synthetic TPP instances and the TPPLIB benchmark demonstrate that our DRL-based approach can significantly outperform well-established TPP heuristics, reducing the optimality gap by 40%-90%, and also showing an advantage in runtime, especially on large-sized instances.