 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Task-driven Discovery of Incomplete Networks
Paper and Code
Sep 16, 2019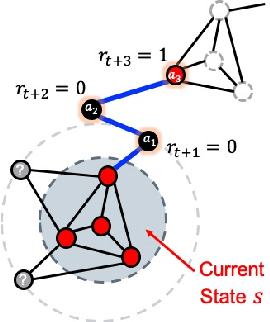



Complex networks are often either too large for full exploration, partially accessible or partially observed. Downstream learning tasks on incomplete networks can produce low quality results. In addition, reducing the incompleteness of the network can be costly and nontrivial. As a result, network discovery algorithms optimized for specific downstream learning tasks and given resource collection constraints are of great interest. In this paper we formulate the task-specific network discovery problem in an incomplete network setting as a sequential decision making problem. Our downstream task is vertex classification.We propose a framework, called Network Actor Critic (NAC), which learns concepts of policy and reward in an offline setting via a deep reinforcement learning algorithm. A quantitative study is presented on several synthetic and real benchmarks. We show that offline models of reward and network discovery policies lead to significantly improved performance when compared to competitive online discovery algorithms.